概率论与数理统计
贝叶斯
我们先看看传说中大名鼎鼎的贝叶斯公式长什么样:
$$ P(\text{假设}|\text{现象}) = \frac{P(\text{现象}|\text{假设}) \ P(\text{假设})} {P(\text{现象})} $$其中:
- $P(\text{假设})$ 是在一开始由我们主观给一个自认为合理的值,叫做先验概率(prior)。
- $P(\text{现象}|\text{假设})$ 叫做似然概率(likelihood)。
- $P(\text{假设}|\text{现象})$ 是我们最后算出来的结果,叫做后验概率(posterior)。
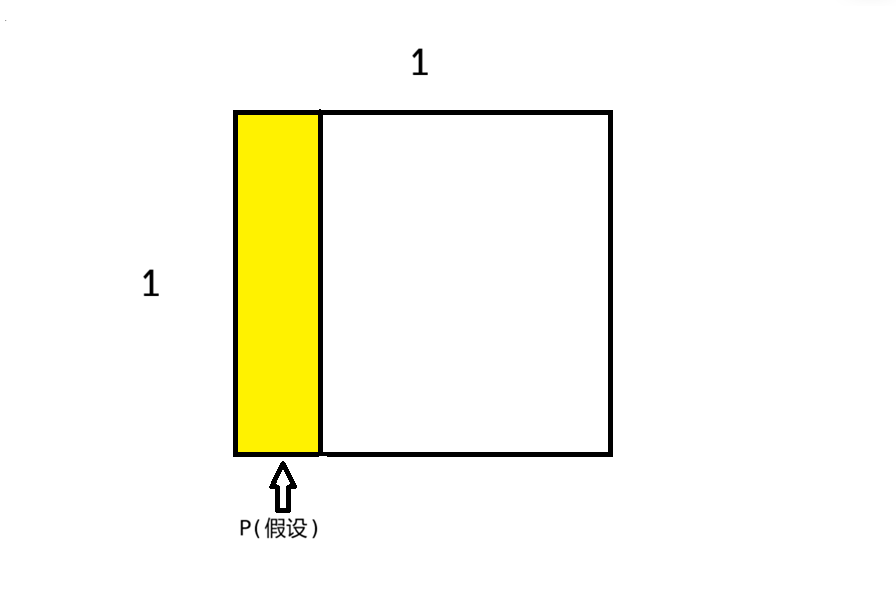
我们现在将整个概率空间想象为一个 $1 \times 1$ 的正方形,此时任意事件都对应该概率空间的一片区域,而事件发生的概率则对应这个区域的面积。
我们可以认为我的假设就是概率空间的左侧区域:
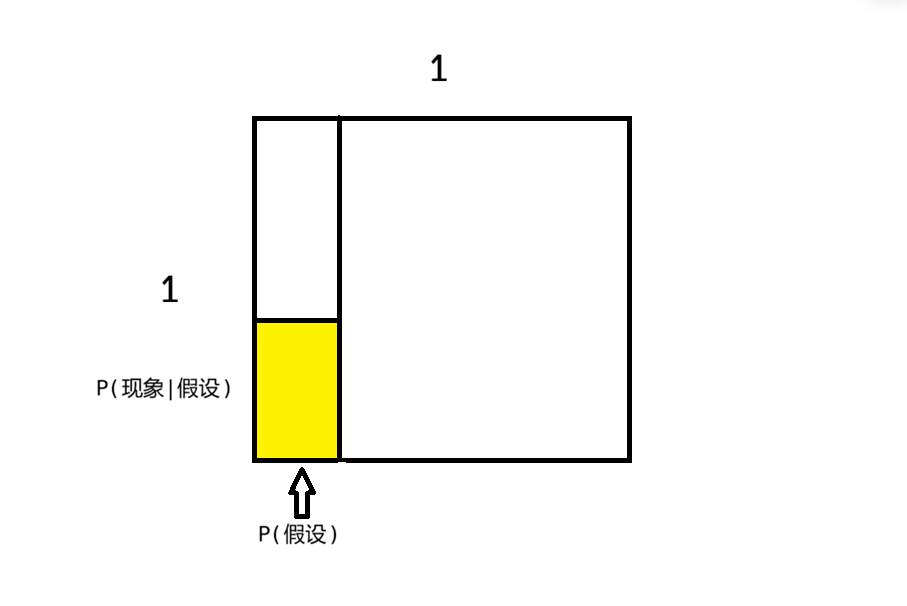
当我们看到现象的时候,概率空间就被限制了:
关键是,对于左边和右边,限制程度是不一样的
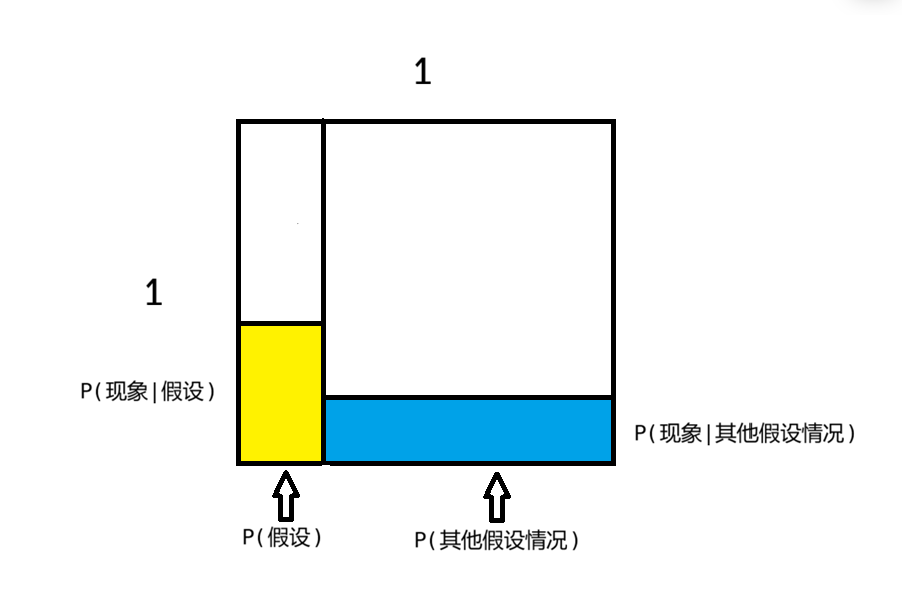
注意到,图中面积的实际意义意味着:
$$ P(\text{假设}|\text{现象}) = \frac{S_\text{假设区域中发生现象}} {S_\text{发生现象}} = \frac{S_\text{黄}} {S_\text{黄}+S_\text{蓝}} = \frac{P(\text{现象}|\text{假设}) \ P(\text{假设})} {P(\text{现象})} $$正态分布
正态分布那个复杂的概率分布公式不是凭空出现的,是一步步从需求推导出来的。
🏹 起点:高斯研究误差
高斯在研究天文观测误差时,想找一个函数 $f(x)$ 描述误差的分布,他提出几个合理的假设:
假设1: 误差关于 0 对称:
$$ f(x) = f(-x) $$假设2: 小误差比大误差更常见,即 $x=0$ 是最大值
假设3: 多次独立观测,最可能的真实值是算术平均数(最大似然估计)
🔧 从假设推公式
设观测值为 $x_1, x_2, ..., x_n$,真实值为 $\mu$,误差为 $x_i - \mu$。
联合概率(似然函数):
$$ L(\mu) = \prod_{i=1}^n f(x_i - \mu) $$假设3 说:$\mu = \bar{x}$ 时 $L(\mu)$ 取最大值,即:
$$ \frac{d}{d\mu} \ln L(\mu) \bigg|_{\mu=\bar{x}} = 0 \\[4pt] \sum_{i=1}^n \frac{f'(x_i - \mu)}{f(x_i - \mu)} = 0 $$令 $e_i = x_i - \mu$,要让上式对任意 $x_1,...,x_n$ 成立,需要:
$$ \frac{f'(e)}{f(e)} = c \cdot e \quad \text{(c 是某个常数)} $$这是一个微分方程:
$$ \frac{f'(e)}{f(e)} = ce $$两边积分:
$$ \ln f(e) = \frac{c}{2} e^2 + C_1 \\[4pt] f(e) = A \cdot e^{\frac{c}{2} e^2} $$要让 $x=0$ 是最大值,需要 $c < 0$,令 $c = -\frac{1}{\sigma^2}$:
$$ f(e) = A \cdot e^{-\frac{e^2}{2\sigma^2}} $$最后用归一化条件确定 $A$(概率积分必须等于1):
$$ \int_{-\infty}^{+\infty} A \cdot e^{-\frac{x^2}{2\sigma^2}} dx = 1 $$这里要计算一个著名的高斯积分:
$$ \int_{-\infty}^{+\infty} e^{-\frac{x^2}{2\sigma^2}} dx = \sigma\sqrt{2\pi} $$这个积分怎么算?用一个绝妙的技巧:
令 $I = \int_{-\infty}^{+\infty} e^{-x^2} dx$,计算 $I^2$:
$$I^2 = \int_{-\infty}^{+\infty} e^{-x^2} dx \int_{-\infty}^{+\infty} e^{-y^2} dy = \int\int e^{-(x^2+y^2)} dx\, dy$$换极坐标 $x = r\cos\theta,\ y = r\sin\theta$:
$$I^2 = \int_0^{2\pi} \int_0^{+\infty} e^{-r^2} r\, dr\, d\theta = 2\pi \cdot \frac{1}{2} = \pi$$所以 $I = \sqrt{\pi}$,换元后得 $\sigma\sqrt{2\pi}$
所以:
$$ A = \frac{1}{\sigma\sqrt{2\pi}} $$最终得到:
$$ \boxed{f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}} $$公式不是拍脑袋的,是从"误差对称、小误差更常见、均值是最优估计"这三个假设,一步步推出来的。
中心极限定理
📋 定理陈述
设 $X_1, X_2, ..., X_n$ 是独立同分布的随机变量,均值为 $\mu$,方差为 $\sigma^2$,令:
$$S_n = \frac{X_1 + X_2 + ... + X_n - n\mu}{\sigma\sqrt{n}}$$则当 $n \to \infty$ 时:
$$S_n \xrightarrow{d} N(0, 1)$$🔧 证明工具:特征函数
直接操作概率密度函数很麻烦,用特征函数(Characteristic Function)来证:
$$\varphi_X(t) = E[e^{itX}]$$特征函数有一个关键性质:
$$\text{若 } X, Y \text{ 独立,则 } \varphi_{X+Y}(t) = \varphi_X(t) \cdot \varphi_Y(t)$$加法变乘法,非常方便!
📝 证明过程
第一步:标准化
先对每个 $X_i$ 标准化,令:
$$Y_i = \frac{X_i - \mu}{\sigma}$$则 $E[Y_i] = 0$,$E[Y_i^2] = 1$
$$S_n = \frac{1}{\sqrt{n}} \sum_{i=1}^n Y_i$$第二步:写出 $S_n$ 的特征函数
由独立性:
$$\varphi_{S_n}(t) = \varphi_{\frac{1}{\sqrt{n}}\sum Y_i}(t) = \left[\varphi_Y\!\left(\frac{t}{\sqrt{n}}\right)\right]^n$$第三步:展开特征函数
对 $\varphi_Y(s)$ 在 $s=0$ 处 Taylor 展开:
$$\varphi_Y(s) = E[e^{isY}] = E\left[1 + isY + \frac{(is)^2}{2}Y^2 + O(s^3)\right]$$$$= 1 + is\underbrace{E[Y]}_{=0} - \frac{s^2}{2}\underbrace{E[Y^2]}_{=1} + O(s^3)$$$$= 1 - \frac{s^2}{2} + O(s^3)$$令 $s = \frac{t}{\sqrt{n}}$:
$$\varphi_Y\!\left(\frac{t}{\sqrt{n}}\right) = 1 - \frac{t^2}{2n} + O\!\left(n^{-3/2}\right)$$第四步:取 n 次方,令 $n\to\infty$
$$\varphi_{S_n}(t) = \left[1 - \frac{t^2}{2n} + O(n^{-3/2})\right]^n$$用极限公式 $\lim_{n\to\infty}\left(1 + \frac{a}{n}\right)^n = e^a$:
$$\lim_{n\to\infty} \varphi_{S_n}(t) = e^{-\frac{t^2}{2}}$$第五步:认出结果
$e^{-\frac{t^2}{2}}$ 正好是标准正态分布 $N(0,1)$ 的特征函数!
由特征函数唯一对应一个分布,证明完毕:
$$\boxed{S_n \xrightarrow{d} N(0,1)}$$正态分布是独立随机变量叠加的"吸引子",就像物理里的稳态,无论初始分布是什么,叠加足够多次都会被吸引到它。