MLsys
学习资源:
MLsys 视频:
MLsys
先看一篇入门好文: AI-Infra 总览:构建支撑大规模训练与推理基础设施平台
我们来看看一个完整的 AI Infra 的架构分别都有什么:

AI 硬件体系架构
AI 计算体系
我们先来一句结论: Key Operations is multiply and accumulate($\text{MAC}$) (> 90% computation)
我们定义一个标准的 $\text{MAC}$ 操作为:
- $\text{MAC} = (\text{操作数}_1 \times \text{操作数}_2) + \text{累加器}$
乘积累加操作的重要性显而易见,无论是矩阵求和,还是我们在计算每一个神经元输出时的 $w_1·x_1 + w_2·x_2 + w_3·x_3 + …$ 时,所用到的都是乘积累加操作。
整体看看 AI or 深度学习计算模式:经典模型结构和轻量化模型结构、模型量化和剪枝到大模型分布式并行,从而理解“计算”需要什么?
AI 三大范式编程
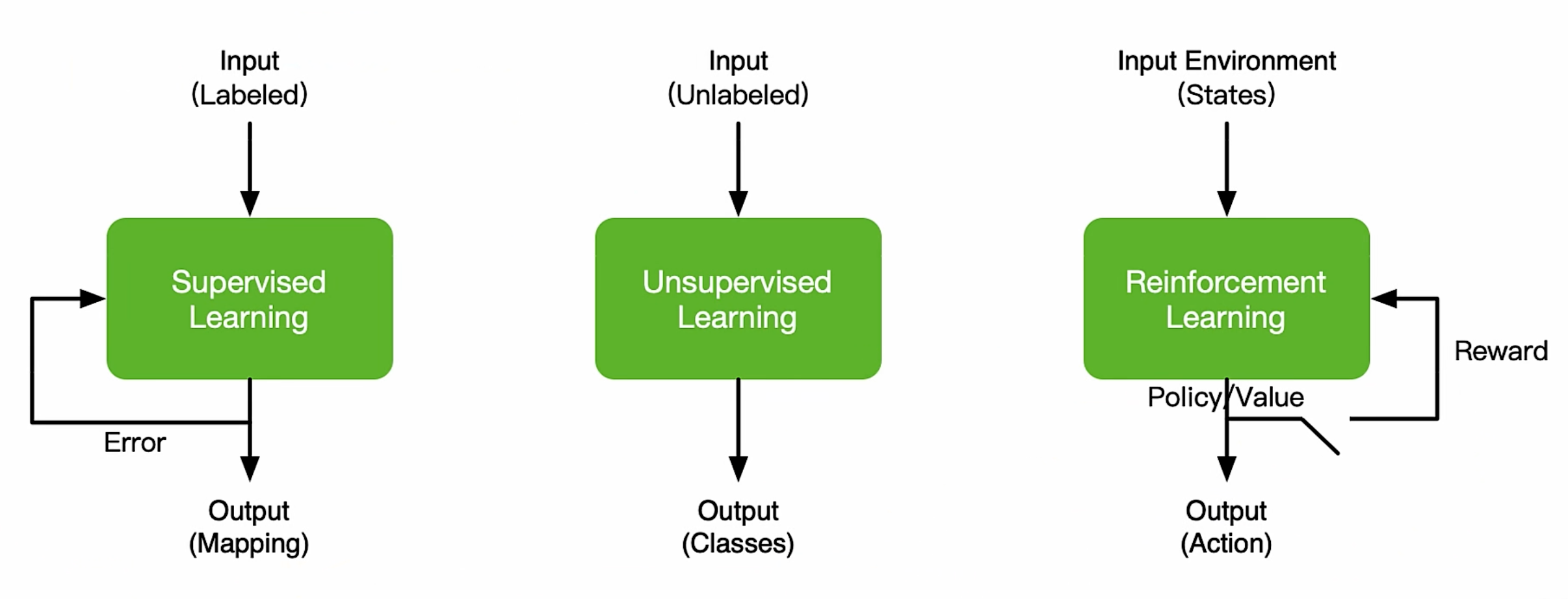
监督学习,无监督学习和强化学习
通过AI芯片关键指标,了解一块AI芯片要更好的支持“计算”,需要关注哪些重要工作;从而引出峰值算力与带宽之间的关系?
算力单位
-
$\text{OPS}$
-
$\text{OPS}$(Operations Per Second) 指每秒计算次数, $1 \text{TOPS}$ 代表每秒进行一万亿($10^{12}$)次计算
-
$\text{OPS/}W$ 指每瓦特运算性能,$\text{TOPS/}W$ 常用来衡量在 1$W$ 功耗下的计算效率
-
-
$\text{MACs}$
- Multiply-Accumulate Operations,乘积累加操作次数,通常 $\text{MACs} = 1次乘法+1次加法 \approx 2 \text{FLOPs}$
-
$\text{FLOPs}$
- Floating Point Operations,浮点运算次数,用来衡量模型计算的复杂度
最后我们通过深度学习的计算核心“矩阵乘”来看对“计算”的实际需求和情况,为了提升计算性能、降低功耗和满足训练推理不同场景应用,对“计算”引入TF32/BF16等复杂多样的比特位宽
矩阵运算
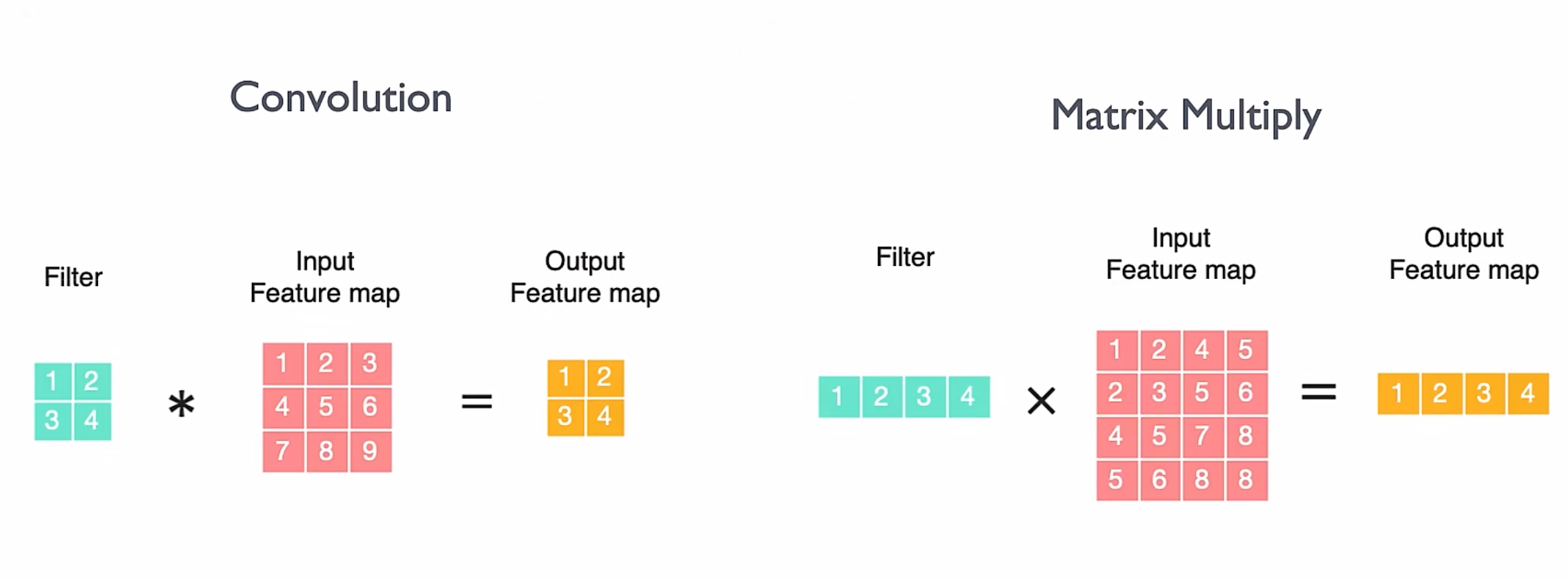
传统的卷积运算,不太好分块进行并行化来优化性能,所以我们一般会将卷积 Conv 转换成 矩阵乘 MM:
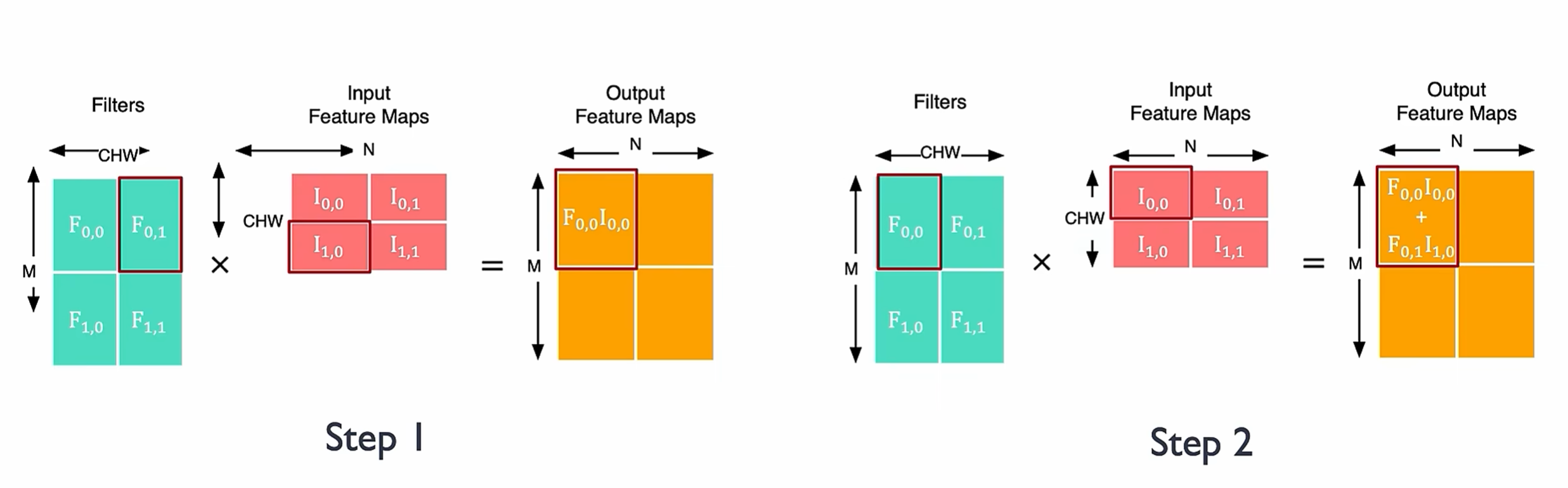
实际中,我们会使用矩阵分块(Tiling) 优化,核心思想就是把大矩阵拆成小块,让每一块刚好能放进高速缓存(Cache)里,从而实现数据重用,用 “空间”(Cache 容量)来换取 “时间”(减少内存访问):
比特位宽

芯片基础
性能指标
计算强度
首先我们来看看什么是计算强度:
$$ \text{Required Compute Intensity} = \frac{\text{算力}}{\text{带宽}} $$假设我们 CPU 的计算能力是 $2000$ $\text{GFLOPS}$ FP64,数据带宽为 $200 \ \text{GB/s}$,那么此时系统中的计算强度等于 $\frac{2000}{200/8} = 80$(除以 8 是因为 FP64 每个数占 8 字节)。这意味着:理论上每加载一次数据后,需要对其进行 $80$ 次计算,才能让算力与带宽恰好达到平衡。
这里我们可以理解为如果带宽很高,然后我们的算力比较小,那么计算就跟不上带宽。这个计算强度的结果代表着每字节数据做多少次浮点运算。
所需线程数
$$ \text{Threads Required} = \frac{\text{带宽} \times \text{时延} }{\text{单次请求数据量}} $$由于内存时延较高,为了让芯片不空转、每时每刻都有数据可以处理,我们需要计算:到底需要多少个并发线程?
例如 Intel Xeon 8280,它的内存带宽为 $131 \ \text{GB/s}$,内存时延是 $89 \ \text{ns}$,那么理论上传输时延这段时间里我们可以传输 $11,659$ Bytes。假设我们这里进行的操作是标准的 $\text{MAC}$ 操作,每次只传输两个数 x 和 y,计算一个 y[i] = alpha * x[i] + y[i],alpha 是一个固定值,因此每个线程每次处理的数据量是 $16$ B,那么如果我们想数据传输的过程中,我们能一直在计算,这时候就可以使用多个线程进行并发。其实这个有点像那个 CPU 中的流水线指令调度一样。
|
|
那么理论上我们需要 $\frac{11659}{16} = 729$ 个线程才可以用满这里的带宽时延
你可能会有这样的疑问: 这里为什么要用多线程呢?难道就不能一个线程连轴转?也就是比如一个线程的寄存器空间有 $256$ kb,然后可以一直往这个寄存器内打数据啊,然后一个线程不停的消费,反正传输时延只在一开始有一次消耗,后面的数据都是一块过来的,消费完继续用不就行了。甚至如果对单次请求的数据进行的计算正好符合计算强度,那不是一个线程就能完美使用了?
这个想法有一个误区,就是一开始执行的时候不一定知道要请求多少数据啊,很可能请求的数据是得计算完成之后才知道,因此每一次请求都会有一个单独的传输时延。因此得靠多线程组成一个类似于流水线,才能保证每次起码有一个 warp 在执行,芯片没有空转
CPU
无论现在 CPU 具体实现怎么变,依旧是由运算器、控制器、寄存器三大部分组成

我们来看一个普通的程序 demo:
|
|
可以看到,循环控制、地址计算等大量工作都由控制器负责,因此实际上: CPU 真正擅长的是逻辑控制,而非密集计算。

因此对于计算密集型的场景, CPU 这种通用结构便力不从心了。CPU 的所有模块,从本质上说都是为了保证指令能一条一条地顺序执行而设计的,所以衡量 CPU 性能的指标是主频(单位时间内执行的指令条数),而不是我们之前提到的 $\text{TOPS}$ (单位时间内的计算次数)。
并行处理硬件架构

这里的指令流可以理解为一次能执行多少种不同运算,数据流可以理解为能同时处理多少份数据。
- SISD(单指令流单数据流):
- 每个指令部件每次仅译码一条指令,而且在执行时仅为操作部件提供一份数据。
- 就是最原始的串行计算方式,完全无法并行计算。在一个时钟周期内,CPU只能处理一个数据流。

- SIMD(单指令流多数据流): 现在用的最多的架构,现在的 Intel 和 AMD 的 CPU 也都是这种
- 一个控制器控制多个处理器,同时对一组数据中的每一个分别执行相同的指令操作。
- SIMD 主要执行向量、矩阵等数组运算,处理单元数目固定,适用于科学计算。
- 特点就是处理单元(PU)数量很多,但是处理单元的速度会受到通讯带宽的限制(因为读取数据是性能瓶颈)

- MISD(多指令流单数据流):作为理论模型出现,没有投入实际的应用之中

- MIMD(多指令流多数据流):是现代多核CPU和分布式系统的基础,使用非常广泛
- 在多个数据集上执行多个指令
- 分为共享内存 MIMD 和分布式内存 MIMD

- SIMT(单指令流多线程): 这是一种和 SIMD 类似的架构,也就是现在 GPU 的主流架构
- 能高效地管理和执行大量单线程,允许同一条指令对多份数据分别寻址并独立执行。
- SIMT 允许每个线程有独立的程序计数器,可以走不同的执行路径(分支),而 SIMD 不行。
- 可以并行执行非常非常多的线程

ISA
用来区分 CPU 的标准是指令集架构 (Instruction Set Architecture, 简称 ISA)。
开发人员基于指令集架构,使用不同的处理器硬件实现方案,来设计不同性能的处理器。
基本分类:
- 运算指令: 在 ALU 中执行的计算操作(AI 专用芯片会专门支持一些特殊的运算指令,这些指令会计算的非常快)
- 数据移动指令: 读写存储操作(包括寄存器的读写)
- 控制指令: 更改指令执行顺序,进行程序跳转,实现 if/else,循环等
ISA 架构
然后 ISA 指令集还分为两种不同的架构:
-
CISC 架构:
- 复杂指令集。计算机上的 CPU 基本都是 CISC 架构。有大量的指令,导致 CPU 的设计变得极其复杂。
- 但是好处是对一些专用的命令速度会非常快,因为直接是硬件支持了,而不是像 RISC 架构一样需要用多条指令来拼凑。
-
RISC 架构:
- 精简指令集。移动设备上的 CPU 基本都是 RISC 架构。
- 只包含处理器常用的指令
ISA 种类
CPU 于上世纪 60 年代问世,已发展几十年,已经有几十种不同的指令集相继诞生或者消亡
| 指令集架构 | 描述 | 公司 |
|---|---|---|
| X86 | CISC 架构个人计算机的标准处理器架构 | Intel/AMD |
| ARM | 32 位和 64 位 RISC 系列声名显赫,无处不在 | ARM |
| RISC-V | 完全开放的指令集,源自名校,兴于开源 | RISC-V 基金会 |
| SPARC | 高性能 RISC 架构的代表,针对服务器领域设计 | Sun |
| Power | RISC 架构高性能领域优势明显,应用于高端服务器 | IBM |
| ARC | 32 位 RISC 架构,以极高的能效比见长 | Synopsys |
| MIPS | 简洁优化 RISC 架构,广泛用于嵌入式设备及消费领域,仅次于 ARM | / |
| Alpha | 64 位 RISC 架构处理器,多应用于企业级服务器,但价格高昂,部署困难,淡出市场 | / |
计算时延模型
首先我们来看看什么是计算强度:
$$ \text{Required Compute Intensity} = \frac{FLOPS}{Data \ Rate} $$假设我们 CPU 的计算能力是 $2000$ $\text{GFLOPS}$ FP64,数据带宽为 $200 \ \text{GB/s}$,那么此时系统中的计算强度等于 $\frac{2000}{200/8} = 80$(除以 8 是因为 FP64 每个数占 8 字节)。这意味着:理论上每加载一次数据后,需要对其进行 $80$ 次计算,才能让算力与带宽恰好达到平衡。
还记得我们上次提到的那个程序 demo 吗?
|
|
这里面涉及到一次乘积累加操作(MAC),它的指令流程如下:
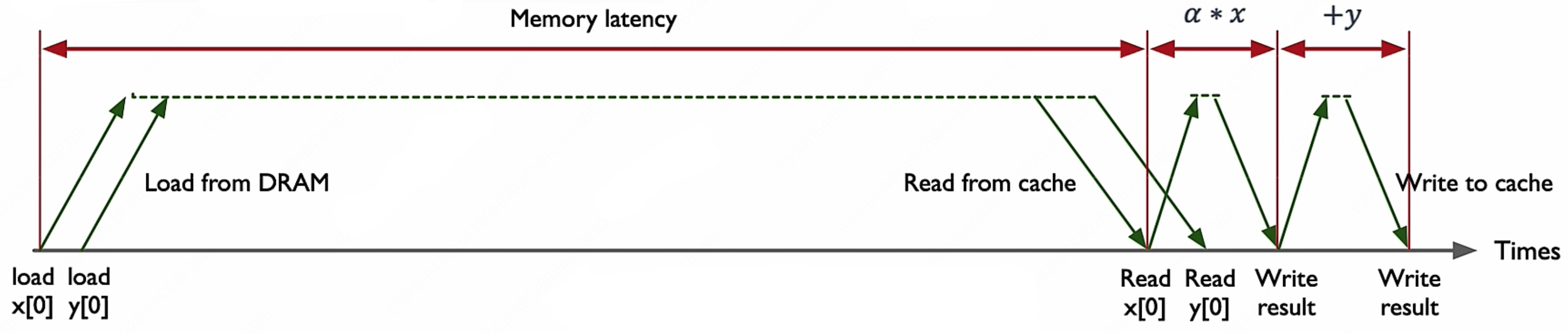
显然,在这个指令执行过程中,内存时延是性能瓶颈。我们可以简单地来算几个数据就知道了:
$$ \begin{align} \text{光的速度} &= 300,\!000,\!000 \ m/s \\ \text{时钟周期} &= 3,\!000,\!000,\!000 \ hz \\ \text{电流速度} &= 60,\!000,\!000 \ m/s \end{align} $$所以最理想的情况下,一个时钟周期内,光可以传播 $10 \ cm$,而电流在硅基芯片中传播速度要慢一点,只能传播约 $2 \ cm$
而我们假设设备配置如下:

那么我们从内存读取数据,最理想的情况下,时延也有 $5∼6$ 个时钟周期了,而由于现在 CPU 的性能过剩,一个时钟周期可以进行很多次计算,因此时延问题成为了我们系统的瓶颈。
实际测试中数据如下:
对于 Intel Xeon 8280,它的内存带宽为 $131 \ \text{GB/s}$,内存时延是 $89 \ \text{ns}$,那么理论上我们可以传输 $11,659$ Bytes 在 $89 \ \text{ns}$ 里。
但是我们刚刚的一次 MAC 而言,我们只传输了 x[i] 和 y[i],一共 $16$ Bytes,只因此在这 $89 \ \text{ns}$ 内,内存利用率只有可怜的 $0.14\%$!
但是更恐怖的是,没有最低,只有更低:

这 $0.14\%$ 一对比发现好像利用率还很高啊!这里的 GPU 的利用率更低,原因在于 GPU 擅长对同一批数据做大量复杂计算(高算术强度),而非像这里每次取完数据只做一次 MAC 这种低强度场景。
GPU
这里我们对 GPU 的讲解都是对 NVIDIA 的 GPU 进行分析,下面不再赘述。
GPU 的设计目标是最大化吞吐量,更关心的是并行度——即同时能执行多少任务;而 CPU 则更注重降低延迟与提升并发能力。
还是回到上面的 demo 的例子,虽然单次我们只请求了 x[i] 和 y[i],一共 $16$ Bytes,内存效率非常低
比如对于上面表格中的 Intel Xeon 8280,理论上一次传输时延的时间里我们可以传输 $11,659$ Bytes,理论上我们需要一次做 $\frac{11659}{16} = 729$ 次计算才可以用满这里的带宽时延
Q. 我们该如何进行优化呢?
首先最直接的想法就是试试增加并发度。
我们可以将上面的 demo 的循环进行展开:
|
|
此时就可以利用上我们之前提到的 SIMD(单指令流多数据流)架构,一条指令就可以同时处理多个数据。
但是问题也很明显,哪怕我们不断地对 CPU 做优化,依旧无法让单个线程单个指令直接处理这 $729$ 个计算负荷啊
既然单线程能力有限,自然会想到:能否用多个线程同时计算,将带宽时延"吃满"?这正是所谓的并行计算。
也就是将上面的 demo 修改为:
|
|
此时情况不一样了:
- 每个线程独立的负责相关计算
- 一共需要 $729$ 个线程
这也就是 GPU 的 SIMT(单指令流多线程)架构在干的事情
我们来看看主流的芯片分别支持多少线程:

这里的 Threads required 是指理论上需要多少线程并行才能填满带宽时延,Threads available 是指这个芯片理论上的可用线程数。
从上图中我们可以看出来,GPU 有着非常非常多的线程,是为大量大规模任务并行而去设计的。
因此:
- GPU 的硬件设计师在不停的将所有的硬件资源投入到增加线程数和增加吞吐上;
- 而 CPU 的硬件设计师则在不断的想办法减少指令执行和数据传输的延迟。
GPU 缓存机制
GPU 中有 SM(Streaming Multiprocessors,流式多处理器)
每个 SM 都拥有私有的寄存器和 L1 级缓存;
所有 SM 共享同一块 L2 级缓存;
此外还有容量巨大的显存(HBM)。
以 NVIDIA A100 为例,Caches 缓存具体有:
| 缓存类型 | 每 SM 容量 | 总容量 | 说明 |
|---|---|---|---|
| 寄存器文件 | $256$ KB | $27$ MB | 每个 SM 私有的最快存储,每个线程独享 |
| L1 缓存 / 共享内存 | $192$ KB | $20$ MB | 可配置为 L1 缓存或共享内存,SM 内线程共享 |
| L2 缓存 | — | $40$ MB | 所有 SM 共享,统一管理 |
它的具体布局如图所示:

各级缓存的性能数据如下:
| 缓存类型 | B/W (GB/sec) | 计算强度 | 时延 (ns) | Threads Required |
|---|---|---|---|---|
| L1 Cache | $19,400$ GB/s | $8$ | $27$ ns | $32,738$ |
| L2 Cache | $4,000$ GB/s | $39$ | $150$ ns | $37,500$ |
| HBM | $1,555$ GB/s | $100$ | $404$ ns | $39,264$ |
| NVLink | $300$ GB/s | $520$ | $700$ ns | $13,125$ |
| PCIe | $25$ GB/s | $6,240$ | $1,470$ ns | $2,297$ |
GPU 模型架构
为了实现用户编程与底层硬件的解耦——即硬件每年迭代升级,用户在 CUDA 层编程时无需感知这些变化——NVIDIA 将 GPU 架构分为硬件架构和软件架构两层,用户不直接操作具体的硬件模块,而是给了一层软件层面的抽象,用户在 CUDA 层进行编程。

接下来我们来慢慢解释这张图上出现的名词和概念。
硬件架构
基本概念:
- GPC: 图像处理簇, Graphics Processing Clusters
- TPC: 纹理处理簇, Texture Processing Clusters。一个 GPC 里有多个 TPC。
- SM: 流多处理器, Stream Multiprocessors。一个 TPC 里有多个 SM。
- HBM: 高带宽存储器(显存), High Bandwidth Memory
- Warp: 线程束,是 SM 的基本执行单元。逻辑上,所有线程都是并行的;但是硬件上,实际执行单元有限,不可能每个线程都在同一时刻执行。因此我们需要一种机制,把大量线程合理地映射到有限硬件上,让 GPU 可以高效调度。于是引入了 warp 概念。
我们打开一个 GPU 中的 SM,看看里面到底都有什么:

对应的具体数据如下:
| 每个 SM | A100 整体 (108 SMs) | |
|---|---|---|
| Total Threads | $2,048$ | $221,184$ |
| Total Warps | $64$ | $6,912$ |
| Active Warps | $4$ | $432$ |
| Waiting Warps | $60$ | $6,480$ |
| Active Threads | $128$ | $13,824$ |
| Waiting Threads | $1,920$ | $207,360$ |
软件架构
基本概念:
- Grid: 网格。表示所有要执行的任务。 Grid 中包含了许多相同线程 Threads 数量的块 Blocks。
- Block: 一个 block 上的 thread 会放在同一个 SM 中进行执行
- Thread: 线程。
我们来结合 CUDA 来介绍这几个概念:
CUDA 引入主机端(Host)和设备(Device)概念。一个 CUDA 程序中既包含 Host 代码,也包含 Device 代码。可以理解为 Host 就是 CPU 要执行的部分, Device 就是 GPU 要执行的部分。这样的话需要大量并行计算的部分就可以通过 GPU 进行运行,然后将结果返回给 CPU。
在 CUDA 程序构架中,Host 代码部分在 CPU 上执行,是普通 C 代码;当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU 能执行的程序,并传送到 GPU,这个程序在 CUDA 里称做 核(kernel)。
Device 代码部分在 GPU 上执行,此代码部分在 kernel 上编写(.cu 文件)。kernel 用 __global__ 符号声明,在调用时需要用 <<<grid, block>>> 来指定 kernel 要执行的具体结构。

具体代码示例:
|
|
kernel 在 Device 中执行时,实际上是启动非常多的线程。一个 kernel 执行所启动的所有的线程被称为一个 网格(grid)
-
Grid 分为多个线程块(block),一个 block 里面包含很多线程。
-
block 间并行执行,并且无法通信,也没有执行顺序。
-
每个 block 包含共享内存(shared Memory),可由里面的 Thread 共享。

Q: 那么这里 CUDA 中引出的软件视角的线程模型和实际的硬件架构有什么关联呢?
- Block 线程块只在一个 SM 上通过 Warp 进行调度。
- 一旦在 SM 上调起了 Block 线程块,就会一直保留到执行完 Kernel。
- SM 可以同时保存多个 Block 线程块,块间并行的执行。
GPU 编程本质
由于有 Img2col 算法的存在,我们可以轻松地将图像处理中使用到的卷积运算转换为矩阵运算,因此 AI 中的绝大多数计算本质上都可以归结为矩阵运算。
而在 AI 计算模式中,不是所有的计算都可以是线程独立的:
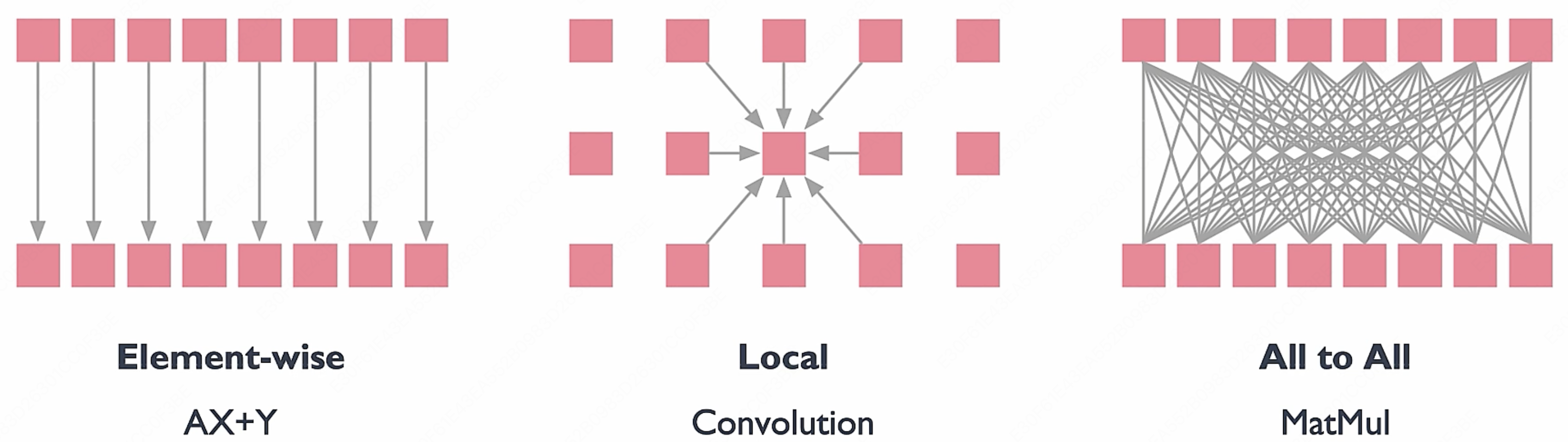
大致可以划分为三种计算模式:
- Element-wise(逐元素操作)
比如 $\text{MAC}$ 操作
- Data Scales = $O(N)$: 数据量随 $N$ 线性增长
- Compute Scales = $O(N)$: 计算量也线性增长
- Intensity = $O(1)$: 两者比值是常数,计算强度不随 $N$ 增大而增大
→ 右边的图是一条水平线,说明不管数据规模多大,每份数据只做固定次数的计算,内存带宽永远是瓶颈,并行帮助有限。
- Local(局部连接)
比如卷积(CNN),每个输出只依赖周围固定窗口内的输入。
- Data Scales = $O(N^2)$: 二维数据,搬运量是 $N^2$
- Compute Scales = $O(N^2)$: 每个输出要计算 $k^2$ 次,输出数据有 $N^2$。($k$ 对于 $N$ 是一个常数)
- Intensity = $O(1)$: 比值依然是常数
→ 图也是水平线,性质和 Element-wise 一样,计算强度没有随规模提升的优势。
- All to All(全连接)
比如矩阵乘法(GEMM)、Attention——每个输出都依赖所有输入。
- Data Scales = $O(N^2)$: 二维数据,搬运量是 $N^2$
- Compute Scales = $O(N^3)$: 每个输出要计算 $N$ 次,输出数据有 $N^2$。
- Intensity = $O(N)$: 计算强度随 N 线性增大!
→ 图是一条斜向上的线,意味着矩阵越大,每次搬运的数据能做的计算越多,硬件利用率越高,越容易打满算力。
因此对于上面的 Element-wise 和 Local 来说,他们的计算强度没有办法通过调整输入的数据规模的增加来线性增加,也就是对于现在更强性能的 GPU 来说,我们没有办法充分地利用日益强大的算力。
因此,All to All 计算模式非常适合 GPU,而矩阵乘法(GEMM)和 Attention 恰好都属于此类,也是当前 LLM 中最核心的计算操作。
我们来看看随着矩阵规模 $N$ 的增大,计算强度和 GPU 硬件对于 FP32 和 FP64 精度的计算强度阈值的对比:
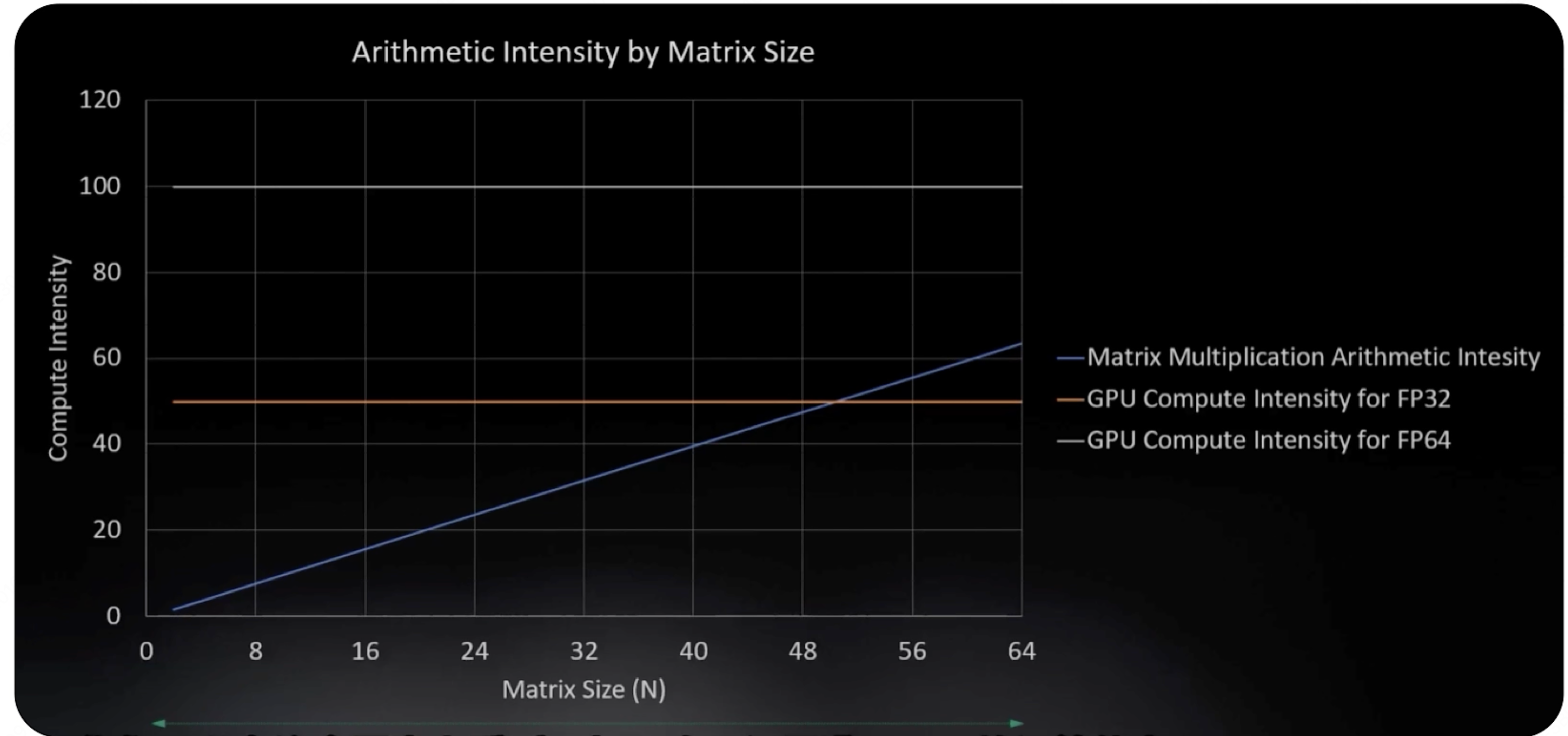
当然,上面说的是一种通用计算的计算强度阈值,NVIDIA 提出了一种专门针对矩阵运算的计算单元: Tensor Core。它对于矩阵运算的计算强度阈值非常高,这样我们就能根据不同的缓存等级来对矩阵规模做更精细化的利用。我们来看看 L1、L2、HBM 的计算阈值分别是多少:
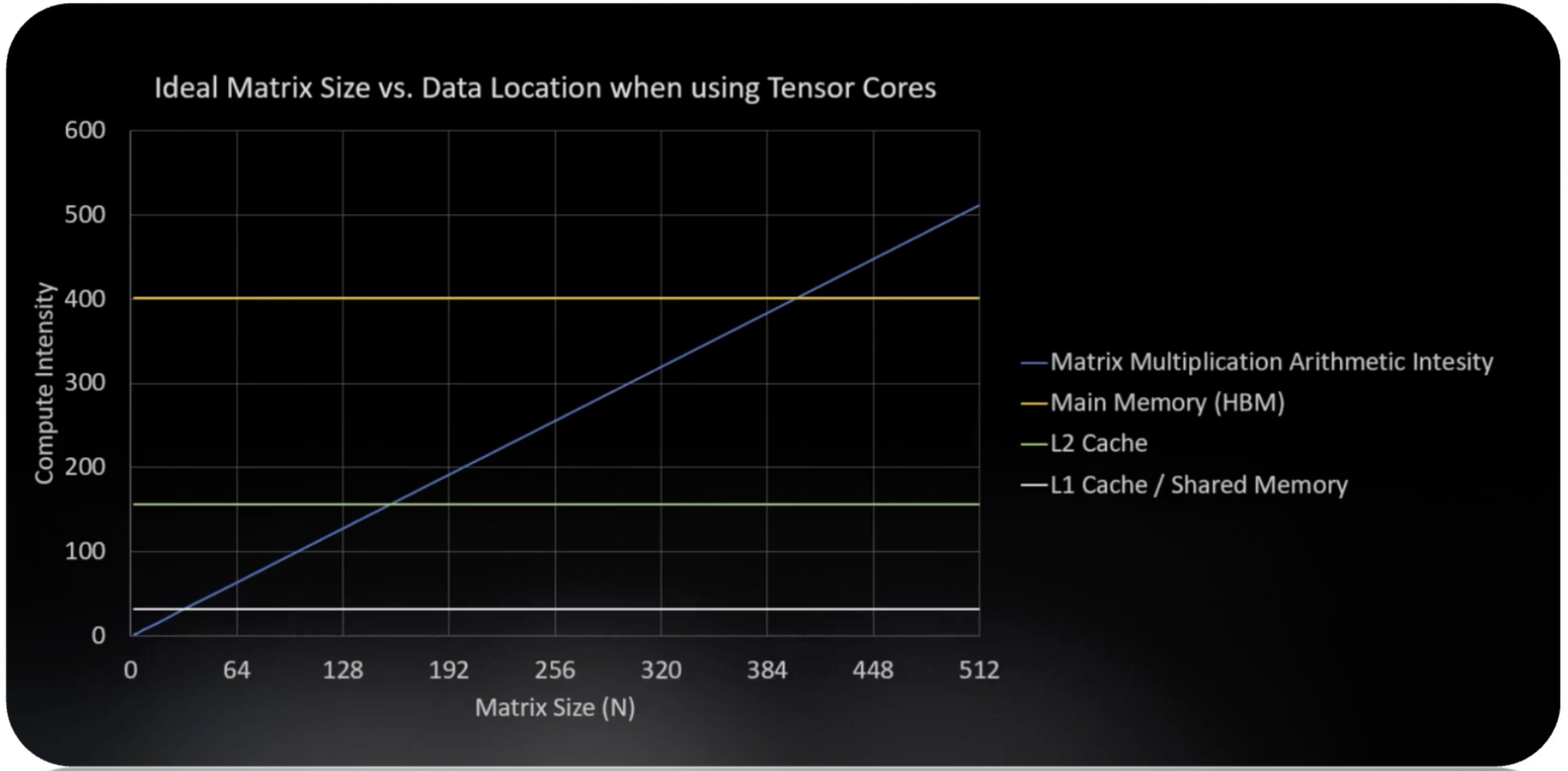
因此我们可以知道,对于 L1,我们适合用一些比较小规模的矩阵进行运算,因为它的计算阈值比较小。这其实也很好理解,因为 L1 缓存的带宽非常高,数据传输非常快,自然留给我们计算的时间也就不多了。
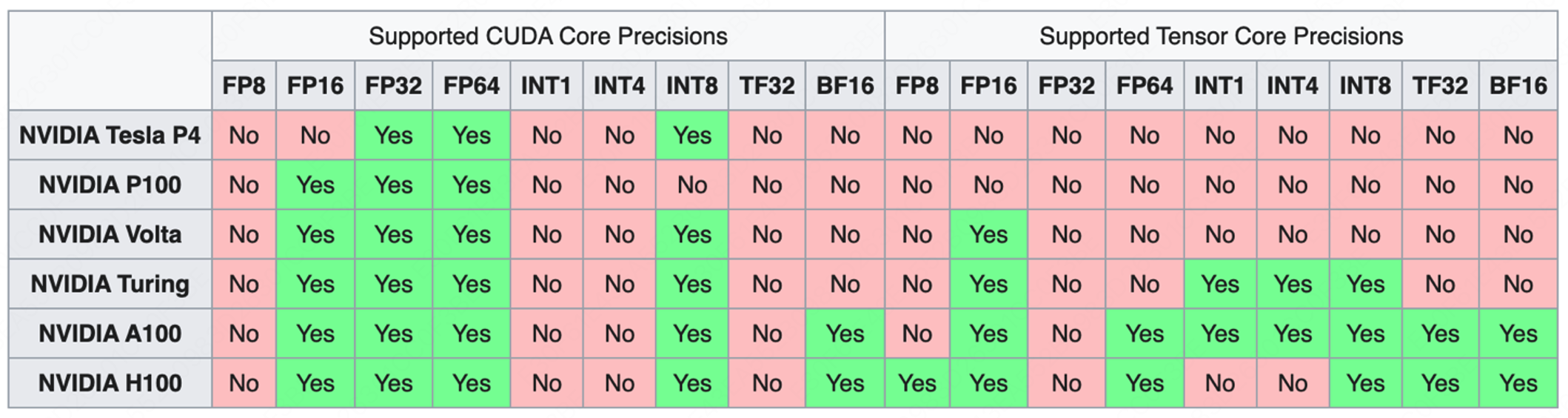
NVIDIA GPU 架构发展
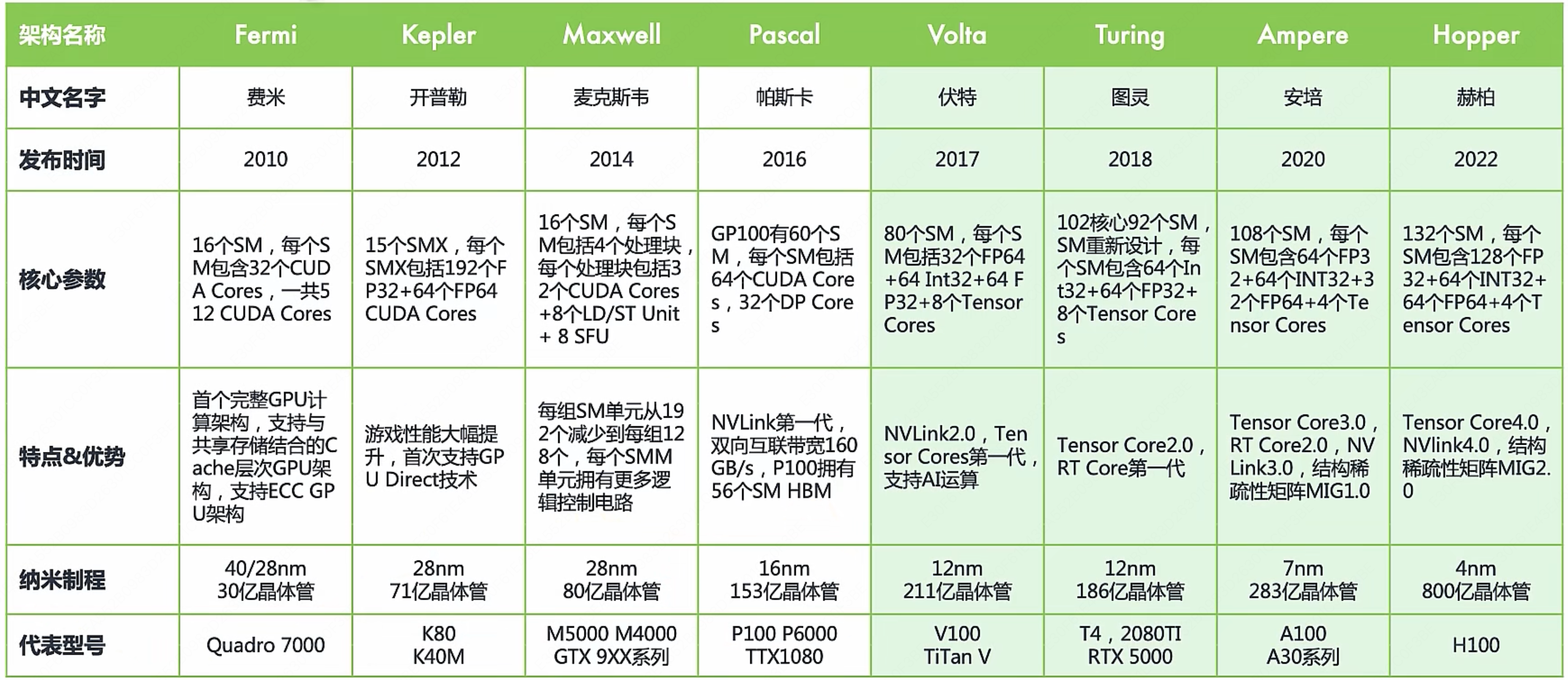
我们可以看到随着 AI 大模型的发展, CUDA Core 逐渐退出了历史舞台,取而代之的是专门做矩阵运算的 Tensor Core。
Tensor Core 原理
在深入探讨 Tensor Core 底层原理以及其对深度学习训练的加速之前,我们首先需要明确一个关键概念——混合精度训练。
这个概念的理解常常困扰很多人,有些人可能会在想,这不就是在训练的过程中同时使用 FP16(半精度浮点数)和 FP32(单精度浮点数)吗?这有啥难的?那你知道为什么要混合着用吗?
混合精度训练实际上是一种优化技术,它通过在模型训练过程中灵活地使用不同的数值精度来达到加速训练和减少内存消耗的目的。具体来说,混合精度训练涉及到两个关键操作:
- 计算的精度分配:在模型的前向传播和反向传播过程中,使用较低的精度(如 FP16)进行计算,以加快计算速度和降低内存使用量。由于 FP16 格式所需的内存和带宽均低于 FP32,这可以显著提高数据处理的效率。
- 参数更新的精度保持:尽管计算使用了较低的精度,但在更新模型参数时,仍然使用较高的精度(如 FP32)来保持训练过程的稳定性和模型的最终性能。这是因为直接使用 FP16 进行参数更新可能会导致训练不稳定,甚至模型无法收敛,由于 FP16 的表示范围和精度有限,容易出现梯度消失或溢出的问题。
另外,混合精度训练中通常还会使用损失缩放(loss scaling)技术来对于 loss 进行一定倍数的放大,该放大倍数会进一步作用到梯度上,从而尽量避免训练后期由于梯度过小导致的数值下溢出问题,使得模型参数更新保持稳定。
下面我们以 Volta 架构第一代 Tensor Core 举例
具体而言,混合精度训练每一轮更新的流程如下:
- 将 FP32 的权重转为 FP16,得到一个 FP16 的权重版本用于前向传播过程,同时依然保留 FP32 的权重作为用于后续参数更新的副本。
- Forward 过程使用较低精度进行计算:将 FP16 的激活值(activation)通过 FP16 的各层权重,最终得到 FP16 的 loss。
- Loss Scaling:将 FP16 的 loss 放大若干倍。
- 反向传播:使用放大后的 FP16 loss 进行反向传播,得到 FP16 的梯度(这里的梯度值相比于实际梯度值也是放大后的,其 scale 的倍数等同于上一步 loss scale 的倍数)。由于此时的梯度值是放大后的,因此即便使用 FP16 保存一般也不会出现下溢出问题。
- Gradient Upscaling:将 FP16 的梯度转为 FP32,然后进行反缩放(unscale),得到 FP32 的实际梯度值。这个实际梯度值可能非常小,但此时由于其使用 FP32 进行保存,因此也避免了下溢出问题。
- 最终,使用 FP32 的实际梯度来更新 FP32 的权重副本。

而在混合精度的实现上,其通常需要特定的硬件支持和软件优化。英伟达的 Tensor Core 就是专门设计来加速 FP16 计算的,同时保持 FP32 的累加精度,从而使得混合精度训练成为可能。所以 GPU 上具备 Tensor Core 是使用混合精度训练加速的必要条件。
在具体的运算过程中,Tensor Core 采用融合乘法加法(FMA)的方式来高效地处理计算任务。每个 Tensor Core 每周期能执行 4x4x4 GEMM,共计 $64$ 个浮点乘法累加(FMA)运算。

如上图所示,在执行运算 $D = A \times B + C$,其中 $A、B、C$ 和 $D$ 是 $4×4$ 矩阵。矩阵乘法输入 $A$ 和 $B$ 是 FP16 矩阵,而累加矩阵 $C$ 和 $D$ 可以是 FP16 或 FP32 矩阵。
有人可能会疑惑: $A \times B$ 是 $64$ 次 FMA 运算,然后再 $+\ C$ 应该还有 $16$ 次的 FMA 运算,总共应该是 $80$ 次?
No, Tensor core 在这里运算的时候其实是将 $+\ C$ 放在了开头,这样就可以利用上乘法运算的 $64$ 次运算了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14# 伪代码 def tensor_core(A, B, C): # A: 4×4, B: 4×4, C: 4×4 D = [[0]*4 for _ in range(4)] # 矩阵乘法(用 FMA 实现) for i in range(4): for j in range(4): acc = C[i][j] # 从 C 初始加载 for k in range(4): acc += A[i][k] * B[k][j] # 这是 FMA D[i][j] = acc return D
我们再来看看 CUDA 中是如何实际使用 Tensor Core 的?
在 CUDA 编程体系中,我们并非直接对线程进行控制,而是通过控制一个 Warp,一个 Warp 包含很多线程(通常为 32 个线程),这些线程并行执行,利用 GPU 的并行计算能力。
这里为什么 Tensor Core 每个时钟周期可以执行 $64$ 个浮点乘法累加(FMA),其实就是利用了多线程的功劳。
在实际执行过程中,CUDA 会对 Warp 进行同步操作,确保其中的所有线程都达到同步点,并获取相同的数据。然后,这些线程将一起执行矩阵相乘和其他计算操作,通常以 $16\times16$ 的矩阵块为单位进行计算。最终,计算结果将被存储回不同的 Warp 中,以便后续处理或输出。(这里的 $16\times16$ 是因为一个 tensor core 的“原子操作” $4\times 4$ 矩阵运算实在太小了,就做了一层封装,对外提供更大的 $16\times16$ 的 API 接口)
我们可以把 Warp 理解为软件上的一个大的线程概念,它帮助简化了对 GPU 并行计算资源的管理和利用。我们只需要通过对 Warp 进行组装使用,而无需关注更低一层的线程调度,便可以写出 CUDA 程序来实现高效、快速的并行计算。
CUDA 通过 CUDA C++ WMMA API 向外提供了 Tensor Core 在 Warp 级别上的计算操作支持。这些 C++ 接口提供了专门用于矩阵加载、矩阵乘法和累加、以及矩阵存储等操作的功能。其中的 mma_sync 就是执行具体计算的 API 接口。借助这些 API,开发者可以高效地利用 Tensor Core 进行深度学习中的矩阵计算,从而加速神经网络模型的训练和推理过程。
|
|
其中:
fragment:Tensor Core 数据存储类,支持matrix_a、matrix_b和accumulator;load_matrix_sync:Tensor Core 数据加载 API,支持将矩阵数据从 global memory 或 shared memory 加载到 fragment;store_matrix_sync:Tensor Core 结果存储 API,支持将计算结果从 fragment 存储到 global memory 或 shared memory;fill_fragment:fragment 填充 API,支持常数值填充;mma_sync:Tensor Core 矩阵乘计算 API,支持 $D = A \times B + C$ 或者 $C = A \times B + C$。
我们来看一个简单的使用例子:
|
|
那我们之前看到的也只是 $16 \times 16$ 的矩阵运算,现在的 LLM 中都是类似于 $2048 \times 2048$ 这样的大矩阵的运算,这是怎么做到的呢?

本质上会通过硬件的多级缓存机制,通过分块去计算,最终通过 tensor core 去完成计算。
下面我们再来看看 Tensor Core 的历代发展:
TPU
网络
RDMA
RDMA(Remote Direct Memory Access),远程直接内存访问。
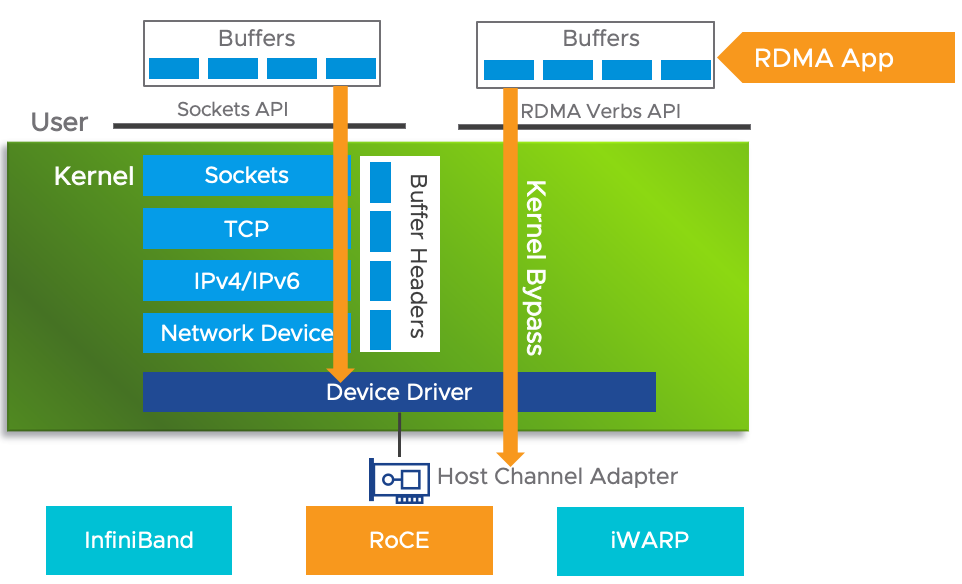
我们来捋一下传统网络数据传输需要哪些步骤:
数据发送方:
- 数据从用户空间 Buffer copy 到内核空间的 Socket Buffer
- 数据在内核空间中加上了数据包头部,进行数据封装
- 最终封装好的数据包从内核 Socket Buffer 通过 DMA 传输到 NIC 发送队列
显然上述做法存在很大的网络时延,带来了两个问题:
- 需要 CPU 多次介入,大量消耗 CPU 性能
- 至少有两次 copy,严重限制了网络带宽
其实,超算的硬件是目前地球上计算机的顶配,对应的技术自然也是最先进的,人们早就研究出了所谓的 InfiniBand(无限带宽技术)来优化超算的网络。
我们需要思考的是如何将这种技术用在现在更大规模的网络和 AI 训练推理中。
人们提出了多种方案,我们介绍其中的两种: TOE 和 RDMA
TOE (TCP/IP 协议处理工作从 CPU 转移到网卡)
这是一种将 TCP/IP 协议处理工作从 CPU 转移到网卡的技术,解决了上面我们提到的问题1。
TOE(TCP Offloading Engine),在主机通过网络进行的传输的过程中,CPU 需要耗费大量的资源进行多层网络协议的数据包处理,包括数据复制、协议处理和中断处理。为了将 CPU 从这些操作中解放出来,人们发明了 TOE 技术,将上述工作从 CPU 转移到了专门的网卡上。TOE 技术需要特定支持 Offloading 的网卡,这种特定网卡能够支持封装多层网络协议的数据包。

- TOE 技术将原来在协议栈中进行的IP 分片、TCP 分段、重组、checksum 校验等操作,转移到网卡硬件中进行,降低系统 CPU 的消耗,提高服务器处理性能。
- 传统的普通网卡处理每个数据包都要触发一次中断,TOE 网卡则让每个应用程序完成一次完整的数据处理进程后才触发一次中断,显著减轻服务器对中断的响应负担。
- TOE 网卡在接收数据时,在网卡内进行协议处理,因此,它不必将数据复制到内核空间缓冲区,而是直接复制到用户空间的缓冲区,这种“零拷贝”方式避免了网卡和服务器间的不必要的数据往复拷贝。
RDMA (绕过CPU,数据直接’传’到对端内存)
TOE 技术只支持 TCP/IP 协议栈,为了进一步优化网络,我们需要绕开 TCP,使用一种自己设计的全新的协议,这样更快,在更小的网络范围内可以使得协议栈更精简。
TOE vs RDMA 对比:
| 特性 | 传统网络 | TOE | RDMA |
|---|---|---|---|
| CPU 参与 | 高(多次中断+数据拷贝) | 低(协议处理卸载到网卡) | 极低(完全绕过内核) |
| 数据拷贝 | 至少 2 次 | 1 次(零拷贝到用户空间) | 0 次(直接内存访问) |
| 协议栈 | TCP/IP | TCP/IP | 自定义(IB/RoCE/iWARP) |
| 网络要求 | 通用 | 通用 | 部分需要无损网络 |
| 延迟 | 高 | 中 | 低 |
| 硬件成本 | 低 | 中 | 高 |
RDMA 利用 Kernel Bypass 和 Zero Copy 技术提供了低延迟的特性,同时减少了CPU占用,减少了内存带宽瓶颈,提供了很高的带宽利用率。RDMA提供了给基于 IO 的通道,这种通道允许一个应用程序通过 RDMA 网卡对远程的虚拟内存进行直接读写。
RDMA 技术有以下几个特点:
- CPU Offload:无需 CPU 干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何 CPU。远程主机内存能够被读取而不需要远程主机上的进程(或 CPU)参与。远程主机的 CPU 的缓存(cache)不会被访问的内存内容所填充
- Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的 TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
- Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
最后的数据包结构如下图所示:

报文结构(从左到右)
- PRE:前缀(Start Delimiter),用于标识报文开始。
- LRH:本地路由头(Local Routing Header),用于本地子网内的路由。
- GRH:全局路由头(Global Routing Header),用于跨子网的路由。
- BTH:基础传输头(Base Transport Header),定义 RDMA 操作类型(如读、写、发送)。
- ETH:以太网帧头(如果 RDMA 运行在以太网之上,即 RoCE 协议)。
- Payload:要传输的实际数据。
- CRCs:循环冗余校验码,用于数据完整性校验。
其中,LRH + GRH + BTH + ETH 合称为 EXTENDED TRANSPORT HEADER(扩展传输头)。
RDMA 是一种设计模式,对应着可以有不同的具体的实现,目前主流有三种:
-
InfiniBand(IB): 基于 InfiniBand 架构的 RDMA 技术,需要专用的 IB 网卡和 IB 交换机。从性能上,很明显 Infiniband网络最好,但网卡和交换机是价格也很高。
-
RoCE:即 RDMA over Ethernet(RoCE), 基于以太网的 RDMA 技术,也是由 IBTA 提出。RoCE 支持在标准以太网基础设施上使用 RDMA 技术,但是需要交换机支持无损以太网传输,只不过网卡必须是支持 RoCE 的特殊的 NIC。
-
iWARP:Internet Wide Area RDMA Protocal,基于 TCP/IP 协议的 RDMA 技术(在现有 TCP/IP 协议栈基础上实现 RDMA 技术,在 TCP 协议上增加一层 DDP),由 IETF 标准定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术,而不需要交换机支持无损以太网传输,但服务器需要使用支持 iWARP 的网卡。与此同时,受 TCP 影响,性能稍差。
三种 RDMA 实现对比:
| 特性 | InfiniBand | RoCEv1 | RoCEv2 | iWARP |
|---|---|---|---|---|
| 网络层 | L2(链路层) | L2(链路层) | L3(UDP/IP) | L4(TCP/IP) |
| 路由支持 | ❌ 仅子网内 | ❌ 仅子网内 | ✅ 可路由 | ✅ 可路由 |
| 无损网络要求 | ✅ 需要 | ✅ 需要 | ✅ 需要 | ❌ 不需要 |
| 性能 | 最高 | 高 | 高 | 中 |
| 硬件成本 | 最高(专用设备) | 中(RoCE 网卡) | 中(RoCE 网卡) | 低(iWARP 网卡) |
| 网络环境 | 专用 IB 网络 | 以太网 | 以太网 | 以太网/广域网 |
| 适用场景 | 超算中心 | 数据中心内部 | 数据中心/跨机房 | 广域网/混合云 |
显然,IB 技术就是我们上面提到的,用在超级计算机中的,本着只求最强,完全不看性价比,什么都得定制化,所以性能最强,也是实际使用中无法接受的,只能作为一种性能标杆来衡量我们 trade off 的方案的性能怎么样
而 RoCE 可以被认为是 IB 技术的低成本的解决方案,本质上就是显示情况下,基本都是以太网络,我们将协议栈兼容现有的以太网络协议,这样可以更好的直接在我们现有的网络中使用,当然由于为了兼容,肯定要牺牲部分的性能,RoCE协议存在RoCEv1 (RoCE)和RoCEv2 (RRoCE)两个版本,主要区别:
-
RoCEv1是在以太网链路层(L2)之上用 IB 网络层代替了 TCP/IP 网络层实现的 RDMA 协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),所以不支持IP路由功能。
-
RoCEv2是使用以太网 TCP/IP 协议中 UDP+IP 作为IB 网络层(L3)实现,基于 TCP/IP协议的网络层(L3)使得 RoCEv2 数据包可以被路由。(也可在三层做 PFC)
而 iWARP 显然是为了再更宽泛的现有网络中使用,支持了广域网,同时由于 TCP 协议支持了流量和拥塞控制,因此不需要无损传输,当然性能也是最差的
云原生资源编排与调度架构
AI 编译计算架构
大模型训练与推理系统架构
推理
SGLang
一个专门用来学习 SGLang 框架的简化版本: nano-sglang