分布式系统
学习资源:
根据计算机自学指南的评论:
MIT6.824: Distributed System
课程简介
- 所属大学:MIT
- 先修要求:计算机体系结构,并行编程
- 编程语言:Go
- 课程难度:🌟🌟🌟🌟🌟🌟
- 预计学时:200 小时
这门课和 MIT 6.S081 一样,出品自 MIT 大名鼎鼎的 PDOS 实验室,授课老师 Robert Morris 教授曾是一位顶尖黑客,世界上第一个蠕虫病毒 Morris 病毒就是出自他之手。
这门课每节课都会精读一篇分布式系统领域的经典论文,并由此传授分布式系统设计与实现的重要原则和关键技术。同时其课程 Project 也是以其难度之大而闻名遐迩,4 个编程作业循序渐进带你实现一个基于 Raft 共识算法的 KV-store 框架,让你在痛苦的 debug 中体会并行与分布式带来的随机性和复杂性。
所以我选了20版本的,因为21年之后就不是 Morris 教授了 MIT 6.824 Distributed Systems (Spring 2020)
分布式系统
MapReduce
谷歌在 2004 年发表了一篇划时代的论文: MapReduce(论文原文以及翻译在这)
它的核心思想是设计了一种受限的分布式编程模型,将并行执行、任务调度、数据分发以及容灾恢复等系统复杂性,封装在了谷歌用 C++ 实现的 MapReduce 库中。在此之上,用户只需要实现其中确定性的 Map() 和 Reduce() 两个方法,即可在大规模集群上完成分布式计算。
1. 整体架构
首先我们来看看整体架构图:
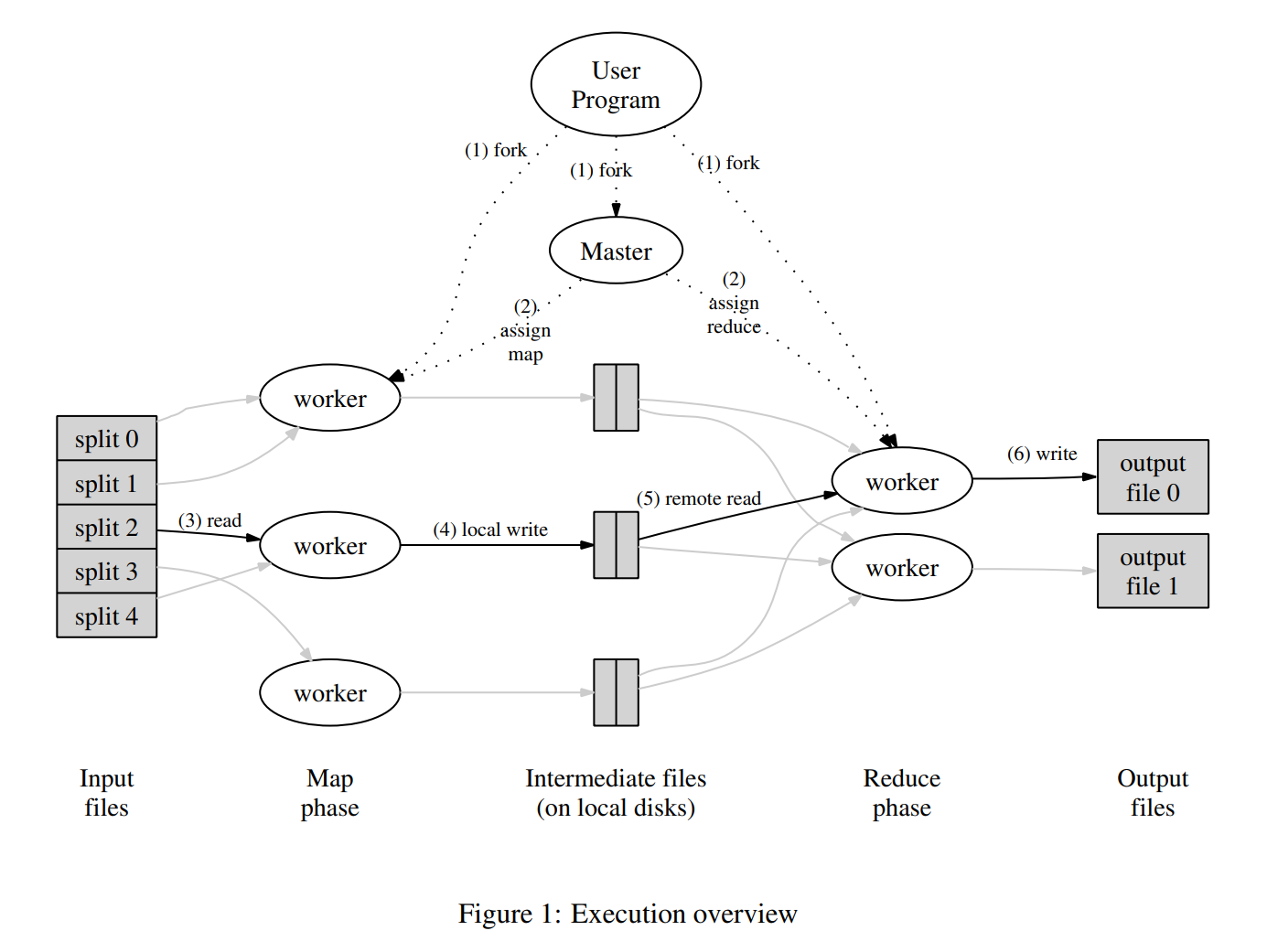
具体操作流程(对应着图中的操作编号):
- 输入数据切分与 worker 启动: 用户程序中运行一个
MapReduce对象任务,MapReduce库首先会将输入文件分割成 $M$ 块数据分片,这些数据分片由大小为 $64\text{MB}$ 的小数据块组成(大小可以自定义),然后在服务器集群中启动多个运行同一个 MapReduce 程序的 worker 进程。 - Master 选举与任务调度: 这些启动的进程中,有一个会被宣布为 Master(主节点),其余的节点都会由主节点进行调度。然后系统中有 $M$ 个 map task(任务) 和 $R$ 个 reduce task(任务) 需要调度。主节点每次都会去寻找空闲的 worker(节点),然后给它调度一个 map 任务或者 reduce 任务。
- Map 任务执行与中间结果生成: 被调度 map 任务的节点 $i$ 都会读取自己这个任务所相应的输入数据分片 $M_i$ (map 任务的数量正好等于划分好的输入数据块的数量),然后从中解析出键值对,用它们作为传参来调用用户自己定义的
Map()方法,并将调用产生的 intermediate key/value pairs(中间键值对)缓存在内存中。 - 中间结果分区与位置汇报: 被调度 map 任务的节点 $i$ 的缓存在内存中的中间键值对会被定期写入这个节点的磁盘中,并且由分区函数来将其划分为 $R$ 个区域(对应的就是 $R$ 个 reduce 任务)。这些区域的地址会被传给主节点,这样主节点就能将位置转发给相应的 reduce 任务的节点,让他进行下一步。
- Shuffle 与排序: 当被调度 reduce 任务的节点 $j$ 收到了来自主节点转发的具体的位置信息,它就可以通过 RPC 来从所有被调度 map 任务的节点产生的第 $R_j$ 个分区中读出中间键值对,然后 copy 到本地。等到所有的中间键值对都拿到了之后,再按照 key 进行排序,用来将相同 key 的 value 放进同一个 list 中。
- reduce 任务执行与结果输出: 被调度 reduce 任务的节点 $j$ 会将相同的 key 的 value 的 list,作为传参来调用用户自己定义的
Reduce()方法。方法的输出会先写入本地的临时文件,待当前 reduce 任务成功全部完成后,再以原子方式写入全局的 GFS 系统中,生成最终的输出文件 $j$。 - 任务完成与用户程序返回: 当所有的 map 任务和 reduce 任务全都执行完,主节点才会唤醒用户程序。这时候用户程序中运行的
MapReduce对象任务也调用返回了。
任务执行结束后,我们会得到 $R$ 个输出文件。一般情况下,用户也不需要将这 $R$ 个文件合并,而是直接作为另一个 MapReduce 对象任务的输入。
2. 系统设计
我们来聊聊 MapReduce 库的底层设计哲学
2.1 编程模型
Map() 和 Reduce() 这两个编程原语来源于 Lisp 和需要其他函数式语言。
作者意识到:大部分的并行计算问题,我们其实都可以表达为一种 MapReduce 计算,即通过对输入数据通过 map函数 映射为一组中间的键值对,然后所有相同 key 的中间键值对由同一个 reduce 函数来完成处理。
比如我们来看看经典的词频统计问题是如何通过 MapReduce 计算来完成的:
首先我们输入的是一个纯 String 的大文件,我们会读取其中的内容,然后通过 map 将这种字节流映射为单词和它出现的次数,即 <word, counts> 这样的中间键值对。然后许多个不同的 map worker 计算得到的结果会被 reduce worker 进行规约,就是把同一个 word 的 counts 累加起来,得到的就是这个 word 最终的结果。
我们用伪代码描述就是下面这样:
|
|
多么的简洁优雅,又很高效的一种编程范式。
我们的 Map() 和 Reduce() 方法,通常需要设计为一种 pure function 的形式,来符合函数式编程的思想。
这样的话,对于同样的输入来说,输出结果和数学函数一样,是恒定的,那么我们下面的容错机制,就可以设计为只对出问题的任务进行重新调度即可,无需影响太多的其他任务。(这是因为如果不是纯函数的话,我们的结果就和执行顺序有关,这样在实际集群环境下,出问题的话需要全部回滚,影响非常大)
当然出于一些特殊的目的,比如打印输出日志或者进行中间运算过程中的统计计算时,这时候可以考虑不适用纯函数。
2.2 容错机制
worker 故障
主节点通过心跳机制来判断是否有 worker 出现了故障。主节点定期会给每一个 worker 发送心跳确认包,如果一定时间没收到回复,并且重复尝试也无效,就会将其标记为故障。
该 worker 上正在进行的任务会被主节点标记为未执行,需要重新进行调度。
该 worker 上已经完成的任务,需要区分是 map 任务还是 reduce 任务:
- 对于已经完成的 reduce 任务,由于是完成后最终写入了全局的 GFS 文件系统中,所以机器挂了也能读到结果,所以不需要重新执行;
- 对于已经完成的 map 任务,由于中间键值对写入的是本地磁盘,所以会丢失导致无法通过 RPC 访问,因此需要全部重新执行
而对于重新执行的 map 任务来说,我们还需要考虑它对所有的 reduce 任务的影响。主节点会通知所有正在运行的 reduce 任务更新该 map 任务输出的中间键值对的位置信息。
- 对于还未读取该 map 任务输出的中间键值的 reduce 任务,就会去新的地址上去 RPC 访问;
- 已经成功读取完旧的 map 任务输出的中间键值的 reduce 任务,无需回滚或者重新执行,继续执行就好。
2.3 可扩展机制
分区函数
MapReduce 库提供了一个默认的分区函数: hash(key) mod R,这种分区方式在大部分情况下,都可以做到语义上将某些 key 放在同一个分区里,并且在很多时候分区也是比较均匀的。
但是有些时候,出于特殊的目的,我们需要按照其他的方式进行分区,就可以自己指定一个可选的分区函数,来完成这种要求。
合并函数
有的时候,Map 任务产生的中间键值对存在很多重复,而网络传输经常是性能的瓶颈,我们这时候可以通过指定一个可选的合并函数来完成中间键值对的部分合并。
比如我们上面的词频统计任务,Map 任务会产生大量的形如 <"hello", "1"> 的中间键值对,我们可以通过合并函数将它们先累加,这样可以极大的减少输出的中间键值对的文件大小。
参数设置
前面提到:我们将输入文件划分为 $M$ 块数据分片,中间键值对被划分为 $R$ 个区域。
那么 $M,R$ 在实际使用时如何选取比较合适呢?
理想情况下: $M,R$ 应该 $>>$ 集群中的服务器数量,这样才能做到动态的负载均衡,因为这时候每个机器就能执行许多不同的任务了。
但是 $M, R$ 也不能无限的大,因为主节点的调度需要 $O(M+R)$ 时间,然后还得记录 $O(M*R)$ 个状态在主节点的内存的数据结构中。以及 $R$ 还会影响最终输出的文件的数量,所以我们需要一个 trade off。
在实践中,我们一般将 $M$ 调整的比较大,然后 $R$ 一般是我们集群中的服务器的较小倍数。
在谷歌的论文中指出,它们一般设置 $M = 200,000$ $R = 5,000$ 来进行 MapReduce 计算,集群服务器数量为 $2,000$。
备份任务
实际开发过程中,我们会发现经常会出现长尾任务,这个任务会成为性能瓶颈。比如说一个机器可能大部分的资源被调度到其他的进程任务上,这时候留给我们执行 reduce 任务的资源就会锐减,时间就会大大延长。
这时候我们可以通过备份机制来缓解这个问题。当 MapReduce 操作接近完成时,主节点会调度剩余进行中的任务的备份来执行,这样只要有一个执行完了,我们就认为这个任务完成了。论文中测试发现,这个方法降低了大概 44%。
优化网络传输
网络带宽经常会成为系统的瓶颈,reduce 任务的远程 rpc 调用获取 map 任务产生的中间键值对,会产生大量的网络传输,因此如果想要优化,在实现上可以考虑优先将 reduce 任务调度给执行完 map 任务的机器,这样就能直接本地读取了。如果不存在这样的机器,那也得优先调度给距离数据较近的机器。