程序员面试指南
自我介绍
面试官您好,我叫xx,来自xxxx。本科毕业于电子科技大学软件工程专业,目前是中国科学技术大学软件学院的研二学生。
目前我在百度搜索架构部实习,主要负责基础检索召回服务相关的研发工作,重点参与了 DIDB中 Storelib底层能力建设,包括原地更新的全内存存储格式 设计、属性写入与反查链路优化,在实际业务场景中显著降低了内存占用并提升了稳定性。
此外,我参加了中科院组织的开源之夏活动,为 ApacheFory 开源项目实现了Go方向的编译时代码生成功能,替代运行时反射,并参与了类型分析、确定 性序列化和工具链建设,对系统设计和工程质量有了比较深入的理解。
我的技术栈以 Java、C++ 为主,对 Go 和 python 也有一定的了解,希望能在贵部门进一步学习和成长。谢谢。
Hello interviewer,
My name is xx, and I’m from xx, xx Province. I did my undergraduate studies at the School of Software Engineering, University of Electronic Science and Technology of China, and I’m currently a first-year postgraduate student at the School of Software Engineering, University of Science and Technology of China.
My main programming language is Java, and I also have some knowledge of C++. The projects I’ve worked on include a Snake Battle mini-game, a food exploration note project, and an intelligent medical AI agent project.
According to the training program of our college, we are required to intern in enterprises for practical learning, so I can commit to a stable one-year internship. I would love to have the opportunity to learn in your department.
Thank you.
简历中项目应该按照时间顺序,把最新的项目放在上面
项目介绍:
Apache Fory
1. 项目信息
-
项目名称:为 Fury Go 实现编译时代码生成功能
-
方案描述:
-
总体目标:
- 在编译阶段生成面向 Fury 二进制协议的强类型序列化/反序列化代码,替代反射热路径,保证协议一致性、性能与类型安全。
-
实施思路(项目初期规划):
- 类型发现:通过
go generate/CLI,扫描源码中带//fory:generate注解的结构体,形成待生成清单。 - 类型分析:获取结构体导出字段的编译期类型信息,识别基础类型、字符串、时间类(如时间戳与本地日期)、指针、结构体、切片与映射等;限定映射键为可比较的基础类型。
- 字段排序:按运行时反射路径的分组与规则生成稳定顺序(primitive/final/other/collection/map),组内再按类型与命名排序,确保与反射序列化的字段顺序一致。
- 结构哈希:将字段类型映射为协议类型标识并迭代计算结构哈希;对切片/映射使用统一标识;对指针命名结构体按规则取符号;避免零哈希。
- 代码生成:为每个目标类型生成一个序列化器及工厂,注册到运行时;生成强类型
WriteTyped/ReadTyped与接口兼容方法;先读写结构哈希,再按排序顺序逐字段编码/解码。- 写入规则:可引用类型(指针、结构体、字符串等)走带引用跟踪通道;非引用基本类型写非空标识后再写值;字符串写引用标识后写内容;时间写微秒,本地日期写天数并处理零日期标记;切片先写长度后遍历;映射先写长度、对键排序后写入键值对。
- 读取规则:对称恢复并校验结构哈希;字符串先读并丢弃引用标识;切片/映射按长度分配或置空;可引用类型走带引用跟踪通道读取并回填。
- 编译期守卫:生成结构体“快照”与编译期校验。当结构体变更但未重新生成时代码无法通过编译,并给出强制刷新与再生成指引。
- 开发体验:提供文件/包/类型多入口与
--force选项;统一注解为//fory:generate;在出现守卫冲突时输出可操作的提示信息。 - 兼容与迁移:生成路径与反射路径保持格式完全一致,可在同一工程内混用并互通,支持按文件/类型的增量引入。
- 测试与验证:构造包含基础类型、切片、映射、指针与嵌套的样例结构体;对比反射与生成路径的二进制;验证读写互通与确定性排序;覆盖零值与引用回路等边界。
- 风险与应对:针对键排序一致性、变长编码差异、可寻址性、零日期语义等风险,分别通过显式排序、遵循协议编码 API、可寻址写入与专门分支规避。
- 验收标准:能为 Struct/Slice/Map 生成零反射开销的序列化器;与反射路径二进制完全一致;守卫可检测失配并提供清晰恢复路径;可无侵入增量接入。
- 类型发现:通过
-
-
时间规划:
- 7 月:熟悉仓库与跨语言协议;学习 Java/Python 版本实现;设计 Go 端 AOT 方案与文件结构
- 8 月下:提交首个 PR(Struct 代码生成,先支持基础类型)
- 9 月中:提交第二个 PR(扩展支持 Slice)
- 9 月下:提交第三个 PR(扩展支持 Map);完善 CLI、文档与测试,收尾优化
2. 项目进度
已完成工作
-
编译时代码生成全链路
- 元信息解析与类型分析:
parser.go、utils.go - 代码生成核心:
encoder.go(WriteTyped)、decoder.go(ReadTyped)、generator.go - 编译期一致性保护(结构体快照与强校验):
guard.go - CLI 工具与使用指引:
cmd/fory/main.go、README.md
- 元信息解析与类型分析:
-
支持的类型与特性
- Struct:基础类型、命名类型(含
time.Time、fory.Date)、指针、嵌套结构体 - Slice:支持任意维度嵌套 slice 的序列化与反序列化
- Map:对基本可比较键的 Map,按键排序实现确定性序列化
- 引用追踪与接口兼容:生成强类型
WriteTyped/ReadTyped,并生成reflect.Value兼容接口方法 - 字段排序与结构哈希:复刻反射路径排序与哈希规则,确保跨语言/反射路径完全一致
- Struct:基础类型、命名类型(含
-
体验与一致性改进
- 生成文件包含
init()自动注册,零显式接线 - 统一注解从
//fory:gen调整为更语义化的//fory:generate - CLI 支持
--force自动清理并重试,缓解编译期快照失配引发的错误
- 生成文件包含
-
测试与示例
- 新增/完善
tests/structs.go覆盖 Struct、Slice、Map、动态切片等示例类型(如ValidationDemo、SliceDemo、DynamicSliceDemo、MapDemo) - 生成器及跨语言模式相关用例:
tests/generator_test.go、tests/generator_xlang_test.go
- 新增/完善
遇到的问题及解决方案
-
反射路径对齐与排序一致性
- 问题:生成代码需与反射序列化在字段排序、类型分组、哈希计算上完全一致,否则跨语言/回放失败。
- 方案:严格复刻反射实现的分组与排序规则;哈希计算对 Slice/Map 采用统一 TypeId(如 LIST=21、MAP=23);为
int、string等细节做特判,保证编码一致。
-
可空与引用追踪
- 问题:区分可引用类型与非引用类型的头标识(RefValueFlag/NotNullValueFlag),以及字符串/指针等路径的差异。
- 方案:在生成代码中统一通过
WriteReferencable/ReadReferencable或非引用路径写入正确标识;字符串等最终类型按协议处理。
-
特殊类型与零值语义
- 问题:
time.Time与fory.Date在协议中的编码语义不同(如本地日期零值标记)。 - 方案:为这两类命名类型生成专门分支,零值与时间单位严格按协议读写。
- 问题:
-
Map 确定性输出
- 问题:Go map 无序,跨平台/回放可能不一致。
- 方案:对不同键类型生成相应的排序逻辑(string/int/uint/float/bool),确保序列化稳定。
-
Varint 编码与类型位宽
- 问题:部分基础类型在反射路径使用变长编码(如 int32/int64);若不一致会导致不兼容。
- 方案:在非引用路径下为对应类型使用变长编码 API,保证与反射路径完全一致。
-
编译期守卫导致的首次失败
- 问题:结构体变更后未重新生成会触发守卫,造成一轮编译失败。
- 方案:CLI 增加智能提示与
--force清理重试;文档同步指引。
后续工作安排
- 类型支持拓展:
set、array、更丰富的 map 键类型、enum/decimal 等 - 兼容模式完善:元共享(MetaShare)与 schema 演进场景代码生成
- 工具链与稳定性:增加 Reflect vs Codegen 对照测试、fuzz 测试、性能基准与 CI 校验
- 生态完善:更多示例与最佳实践文档,支持更细粒度的生成选项(按包/按文件/按类型)
- 代码质量:进一步收敛边界分支(指针可寻址性、接口落地类型),提升可维护性
小智医疗
嵌入模型:阿里云百炼平台嵌入模型 text-embedding-v3,向量维度1024
持久化数据库:MongoDB
向量数据库:Pinecone。通过设置 minScore 阈值,能够过滤掉那些与查询文本相关性较低的结果
分片方式:按段落分割文档:每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性
流式输出:修改chatModel为streamingChatModel = "qwenStreamingChatModel",并修改chat方法返回值为Flux<String>
@AiService:
Function calling:用 @Tool 注解的方法,并配置工具名称和描述
探店笔记
项目介绍
仿大众点评 APP,实现了用户登录、关注、发布推送博客以及优惠券秒杀等功能,用户可以浏览首页热门内容,搜索查看附近商家,发布及查看探店博客。
主要功能模块
1.登录
因为如果使用Session在集群不同服务器之间无法共享,所以我们选择借助可以自动进行数据共享的Redis+token的存储方式。
这里有三个细节:
- 用户脱敏的处理:不能将从MySQL中取出来的用户的所有信息都直接在浏览器间传输(需要保护敏感信息),所以需要将基本可展示的属性封装成单独的DTO进行传递
- 使用双拦截器进行刷新token以及登录验证:如果只用一个拦截器,是无法完成对所有页面刷新token以及对于需要登录的页面进行登录验证的,所以我们设计了双拦截器模式,第一层拦截器会对所有的页面放行,同时刷新用户token的有效期,第二层拦截器会对需要登录的页面进行登录验证。
- 在第一层拦截器使用 ZSet 结合时间窗口进行登录限流。通过每次用户发起登录请求时,向 ZSet 插入一个 以当前时间戳为
score和member的记录;然后使用ZREMRANGEBYSCORE删除 窗口开始时间之前 的所有记录(滑动窗口的核心);最后通过ZCARD获取 ZSet 中剩余成员的数量(即当前窗口内的请求次数),将超过阈值的用户触发限流,拒绝请求。(通过 Lua 脚本 将ZADD+ZREMRANGEBYSCORE+ZCARD合并为原子操作,避免并发问题)
面试题:讲讲Session和Token的区别
维度 Session Token 存储位置 服务端存储(如 Redis、DB) 客户端存储(如 Cookie、LocalStorage) 状态性 有状态(服务端维护会话) 无状态(服务端不存储) 典型实现 Session ID + 服务端存储 JWT、OAuth2 Token 扩展性 跨服务器需共享存储 天然支持分布式 安全性 依赖服务端保护 需防篡改(如签名/加密)
token可以优化成JWT格式(私钥和公钥)
2.商户缓存
细节点:
2.1 双写一致性:
数据库与缓存数据不一致的问题:
- 查:如果缓存未命中,就查询数据库,将结果写入缓存,并设置超时时间
- 改:先修改数据库,再删除缓存。
2.2 缓存穿透问题:
- 缓存并缓存空对象,项目中就用的这个
- 布隆过滤器(实现比较复杂)
2.3 缓存击穿问题:
- 使用互斥锁:这里借助Redis提供的
setnx方法来实现,本项目就是使用的这个。 - 逻辑过期:异步构建缓存
3.优惠卷秒杀
基于Redis的setNx方法使得满足分布式系统下多进程可见并且互斥的锁。
细节点:
- 利用setnx方法进行加锁,同时增加过期时间,防止死锁。
- 释放锁时防误删(使用Lua脚本:在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的)
- 一人一单:比如时间是否充足,如果时间充足,则进一步判断库存是否足够,然后再根据优惠卷id和用户id查询是否已经下过这个订单,如果下过这个订单,则不再下单,否则进行下单
优化: 采用消息队列去将判断和执行操作进行异步化。
- 新增秒杀优惠卷的同时,将优惠卷信息保存到Redis中
- 基于Lua脚本,判断秒杀库存,一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠卷id和用户id封装后存入消息队列(这里我们使用Redis中的Stream作为消息队列)
- 开启线程任务,不断从消息队列中获取信息,实现异步下单操作
4. 达人探店
4.1 实现一个人只能点赞一次
- 给Blog类中添加一个isLike字段,标示是否被当前用户点赞
- 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
4.2 共同关注功能
- 当然是使用我们之前学习过的set集合咯,在set集合中,有交集并集补集的api,我们可以把两人的关注的人分别放入到一个set集合中,然后再通过api去查看这两个set集合中的交集数据。
4.3 好友关注-Feed流实现方案+滚动分页的实现
5. 查看附近商户
使用Redis的GEO数据结构存储经纬度,实现附近商户查询功能。
当我们点击美食之后,会出现一系列的商家,商家中可以按照多种排序方式,我们此时关注的是距离,这个地方就需要使用到我们的GEO,向后台传入当前app收集的地址(我们此处是写死的) ,以当前坐标作为圆心,同时绑定相同的店家类型type,以及分页信息,把这几个条件传入后台,后台查询出对应的数据再返回。
我们要做的事情是:将数据库表中的数据导入到redis中去,redis中的GEO,GEO在redis中就一个menber和一个经纬度,我们把x和y轴传入到redis做的经纬度位置去,但我们不能把所有的数据都放入到menber中去,毕竟作为redis是一个内存级数据库,如果存海量数据,redis还是力不从心,所以我们在这个地方存储他的id即可。
但是这个时候还有一个问题,就是在redis中并没有存储type,所以我们无法根据type来对数据进行筛选,所以我们可以按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可
6.全局唯一id
这个需要通过redis实现分布式id
为了提高数据库的性能,id会采用数值类型(Long)直接插入数据库(因为数值类型在数据库中占用空间较小,建立索引方便,速度更快)。
因为采用的是Long型,有8个字节,64个比特位,
第一个比特位是符号位,永远为0。
中间31个bit为时间戳(以秒为单位,定一个初始的时间,在计算下订单时的时间与初始时间的时间差是多少秒并记录下来,可以使用69年),用来增加ID复杂性,不是单纯的Redis自增。
后面32位bit为序列号,序列号中就是Redis自增的值。支持每秒产生2^32个不同ID
因此如果在一秒钟下了多份订单,即使时间戳相同,那么后面的序列号也会不同。
综上所述,利用redis就能够满足分布式系统中全局唯一ID的五大特性。 注意事项:不能只选择一个key来坐自增长,即无论订单业务持续多长时间,自始至终就只是这一个key在做自增长,随着不断的发展,key的值会也来越大,而redis单个key的自增长的数值是有限度的,上限为2 ^ 64。而且真正用来记录的序列号只有32位bit,如果接下来存的数值超过了2^32位,那么序列号这一部分就存不下。因此不能一直使用同一个key,哪怕是同一个业务。
解决方案,可以在该key后面在拼接一个时间戳,比如哪一天下的订单,当天的key就为 key名+ “20250605”。向下类推。这样还可以统计每一天下单的总量。
|
|
蛇蛇大作战
主要包含模块:
-
pk模块
-
对局列表模块:
-
排行榜模块
-
用户中心模块

websocket(全双工)
KOB项目可能面试题
问题:在实现Bot服务时,如何确保代码的安全性,避免恶意代码的执行?
为确保代码安全性,我们可以对用户提交的Bot代码进行过滤和限制。例如,可以使用沙箱技术隔离代码执行环境,限制代码对系统资源的访问。同时,我们还可以对代码进行静态分析,以识别并阻止潜在的恶意行为。
问题:请谈谈项目中使用WebSocket的优势以及在实际应用中遇到的挑战。
WebSocket的主要优势是提供了一种实时双向通信机制,允许服务器与客户端之间进行低延迟、高效的数据交换。这对于在线游戏这样要求快速响应和实时交互的应用场景非常重要。在实际应用中,我们可能会遇到WebSocket连接不稳定、网络延迟和浏览器兼容性等问题。为了解决这些问题,我们需要确保代码具有足够的容错能力,如重连机制,以及对各种浏览器的充分测试。
问题:在匹配服务中,如何根据玩家的分值差距和等待时间进行智能匹配?
在匹配服务中,我们使用一个定时线程来定期检查待匹配玩家列表。根据玩家的分值差距和等待时间,我们可以为每个玩家计算一个匹配优先级。优先级越高,匹配的可能性越大。我们可以利用优先级队列来快速找到最佳匹配对手。为了实现更精确的匹配,我们可以根据实际情况调整优先级计算的权重和阈值。
问题:在项目中,为什么选择将功能划分为三个独立的SpringBoot进程模块?
将主服务、匹配服务和Bot服务独立出来,可以降低各个模块之间的耦合度,使每个模块专注于自己的功能,便于维护和扩展。
- 可扩展性:各个模块可以根据实际需求进行横向扩展,提高系统的整体性能。
- 容错性:将功能拆分为多个独立的进程可以提高系统的容错性。当某个模块出现故障时,不会影响到其他模块的正常运行。
- 灵活部署:各个模块可以根据实际情况灵活部署,例如在不同的服务器上运行,以满足不同模块的资源需求。
问题:项目中如何实现线程安全的游戏状态同步?
为了实现线程安全的游戏状态同步,我们采用了以下策略:
- 对共享资源进行同步访问:在涉及到多线程访问共享资源的地方,我们使用锁或其他同步机制来保证数据的一致性。
- 尽量减少共享资源:通过将共享资源封装在ThreadLocal中,可以实现线程之间的数据隔离,从而减少同步的需求。
- 优先使用无锁数据结构:在适当的场景下,使用无锁数据结构(如ConcurrentHashMap、AtomicInteger等)可以降低锁竞争带来的性能开销。
问题:在项目中,如何保证Bot代码执行的性能和资源占用?
为了保证Bot代码执行的性能和资源占用,我们采用了以下策略:
- 使用线程池:通过线程池控制并发的Bot任务数量,避免过多的线程导致系统资源耗尽。
- 设置超时限制:为Bot代码执行设置合理的超时限制,防止某些任务长时间占用系统资源。
- 资源限制:为每个Bot任务分配固定的资源,例如CPU和内存,以防止某些任务过度消耗系统资源。
问题:如何保证匹配服务在高并发情况下的性能?
为了保证匹配服务在高并发情况下的性能,我们采用了以下策略:
- 使用高性能数据结构:选择高性能的数据结构(如ConcurrentHashMap、PriorityQueue等)来维护待匹配玩家列表,以减小并发访问的性能开销。
- 异步处理:通过将匹配任务放入队列并采用异步处理方式,可以有效降低用户请求的响应时间。
- 定时线程:使用定时线程按照分值差距和等待时间进行动态配对,减少匹配过程中的计算量。
问题:在实现Bot服务时,如何防止恶意代码的执行?
为了防止恶意代码的执行,我们在Bot服务中采用了以下策略:
- 代码审查:在用户提交Bot代码前,可以通过代码审查工具对其进行安全性检查,过滤掉潜在的恶意代码。
- 沙箱环境:将Bot代码运行在隔离的沙箱环境中,限制其对系统资源的访问,从而降低恶意代码对系统的影响。
- 资源限制:为每个Bot任务分配固定的资源,例如CPU和内存,以防止恶意代码消耗过多的系统资源。
问题:在游戏平台中,如何处理用户的实时在线对战功能?
为了处理用户的实时在线对战功能,我们采用了以下策略:
- WebSocket:使用WebSocket实现双向实时通信,使服务器能够及时将游戏状态推送给客户端,同时接收客户端的操作。
- 多线程处理:针对多对玩家的操作,我们采用多线程处理方式,每对玩家的操作在一个独立的线程中执行,以提高并发处理能力。
- 游戏状态同步:通过服务器端的游戏状态管理和同步机制,确保所有客户端看到的游戏状态是一致的。
项目整体架构类
- 请简要描述这个项目的整体架构,包括前端、后端和数据库的交互流程。
- 项目中使用了哪些微服务?它们之间是如何通信和协作的?
- 请说明项目中不同模块(如匹配系统、对战系统、回放系统)之间的依赖关系和调用逻辑。
技术细节类
前端部分
- 在
web/src/assets/scripts/GameMap.js中,add_listening_events方法在回放模式和正常游戏模式下的处理逻辑有何不同? - 前端使用了哪些技术来实现游戏的动画效果,如蛇的移动和死亡状态?
- 前端如何与后端进行数据交互,特别是在获取对局记录和发送玩家操作方面?
后端部分
- 在
kob/backendcloud/backend/src/main/java/com/kob/backend/consumer/utils/Game.java中,nextStep方法的作用是什么?它是如何实现等待玩家下一步操作的? - 后端使用了哪些技术来实现多线程处理,如
Game类继承Thread类的作用和实现方式? - 请解释
kob/backendcloud/botrunningsystem/src/main/java/com/kob/botrunningsystem/service/impl/utils/Consumer.java中startTimeout方法的作用和实现逻辑。
数据库部分
- 项目中使用了哪种数据库?请说明数据库表结构,特别是与对局记录相关的表。
- 在
kob/backendcloud/backend/src/main/java/com/kob/backend/consumer/utils/Game.java中,saveToDatabase方法是如何将对局信息保存到数据库中的? - 如何保证数据库操作的事务性和数据一致性?
问题解决类
- 如果在对局回放过程中出现卡顿或延迟,你会从哪些方面进行排查和解决?
- 当多个玩家同时请求匹配时,如何处理并发问题,确保匹配系统的稳定性和公平性?
- 如果前端无法获取后端的对局记录,你会如何进行调试和定位问题?
代码优化类
- 请分析
web/src/assets/scripts/Snake.js中update_move方法的性能瓶颈,并提出优化建议。 - 对于
kob/backendcloud/matchingsystem/src/main/java/com/kob/matchingsystem/service/impl/utils/Player.java类,你认为可以从哪些方面进行代码优化? - 如何优化前端的网络请求,减少响应时间和数据传输量?
扩展性和维护性类
- 如果要增加一种新的游戏模式,你会从哪些方面对项目进行修改和扩展?
- 如何保证项目代码的可维护性,特别是在多人协作开发的情况下?
- 请说明项目中使用的依赖管理工具(如
npm和Maven)对项目扩展性和维护性的影响。
c++
可以先看看我的c++学习笔记
c++语法方面的八股可以看:代码随想录(最强八股文)第五版(C++篇).pdf
小红书引擎架构面试原题
Q: 对于一个 struct vector:
|
|
如果我们有线程 a 和线程 b,它们一个在不停的修改 x,一个在不停的修改 y,请问会有性能问题吗?
A: 会有的。因为现代的 CPU cache line 一般为 64 字节,所以整个 vector 会在同一个 CPU cache line 里。
这是一个经典的 False Sharing(伪共享) 问题。
假设:
- 线程 A 跑在 core 0
- 线程 B 跑在 core 1
第一次写:
- core 0 写
x - cache line 被加载到 core 0 的 L1 cache
- 状态变成 Modified (M)
然后线程 B 写 y:
- core 1 想写
y - 根据 MESI 协议:
- core 1 不能直接写
- 必须先让 core 0 的那条 cache line 失效(invalidate)
- cache line 被“抢”到 core 1
- core 1 写
y→ Modified
再轮到线程 A
- core 0 再写
x - invalidate core 1
- cache line 再被拉回 core 0
小红书引擎架构面试原题
Q.
1.我们的程序在执行 char* data = new char[1024 * 1024 * 1024]后,会立马分配 1GB 的内存空间吗?
2.如果我们这时候访问 data[0],os会做哪些事情?
3.malloc 很大的空间和很小的空间会有什么差异吗?
Java代码题
交替打印"ABC"
|
|
|
|
交替打印1-100
|
|
网络
HTTP的常用方法有哪些
- GET
- POST
- DELETE
- PUT
- HEAD
有哪些常用状态码

其中常见的具体状态码有:
- 200:请求成功;
- 301:永久重定向;302:临时重定向;
- HTTP 403 Forbidden 是客户端错误状态码,表示服务器理解请求但拒绝执行,通常是因为客户端没有访问资源的权限。404:无法找到此页面;405:请求的方法类型不支持;401 表示“未授权”(Unauthorized)
- 500:服务器内部出错。
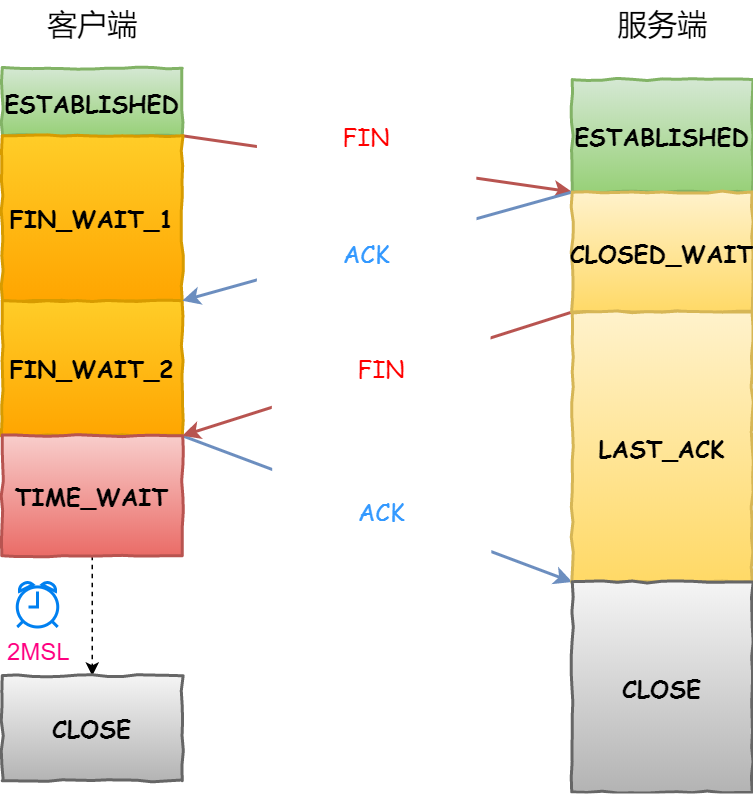
讲一下TCP连接的三次握手和四次挥手
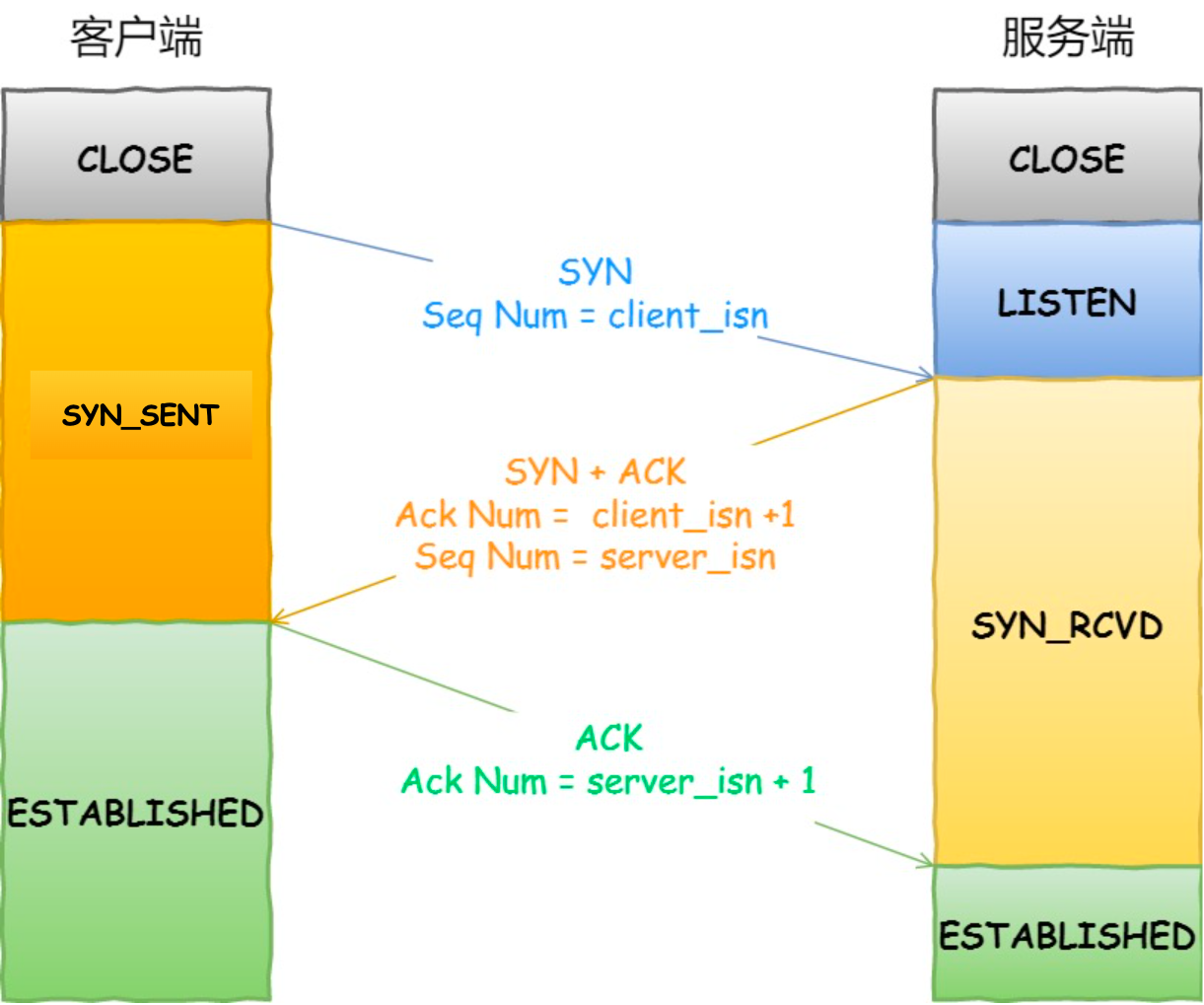
这样双方都完成了一次“发送-收到回复”的过程。
接下来,从三个方面分析三次握手的原因:
1. 三次握手才可以阻止重复历史连接的初始化(主要原因)
我们来看看RFC793指出的TCP连接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations fromcausing confusion.
简单来说,三次握手的首要原因是为了防止旧的重复连接初始化造成混乱。
如果是两次握手连接,就无法阻止历史连接,那为什么TCP两次握手为什么无法阻止历史连接呢?
我先直接说结论,主要是因为在两次握手的情况下,服务端没有中间状态给客户端来阻止历史连接,导致服务端可能建立一个历史连接,造成资源浪费。
2. 三次握手才可以同步双方的初始序号
TCP协议的通信双方,都必须维护一个「序列号」,序列号是可靠传输的一个关键因素,它的作用:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中,哪些是已经被对方收到的(通过
ACK报文中的序列号知道);
3. 三次握手才可以避免资源浪费
即两次握手会造成消息滞留情况下,服务端重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
tcp和udp共用端口的问题
可以的
如何实现一个可靠的UDP
UDP本身是无连接、不可靠的传输层协议,但其低延迟和灵活性使其适用于实时性要求高的场景(如游戏、音视频传输)。若需在UDP基础上实现可靠性,需通过应用层协议设计来弥补其不足。以下是实现可靠UDP的核心方案:
1. 核心机制设计
| 机制 | 实现目标 | 具体方案 |
|---|---|---|
| 序列号 | 确保数据包顺序正确性 | 为每个数据包分配递增的序列号(Sequence Number),接收方按序重组数据。 |
| **确认应答(ACK)** | 确认数据包到达,触发重传 | 接收方收到数据包后发送ACK,携带已确认的最大序列号或选择性确认(SACK)。 |
| 超时重传 | 处理丢包问题 | 发送方维护未确认数据包的计时器,超时后重传。动态计算超时时间(基于RTT)。 |
| 流量控制 | 防止发送方压垮接收方 | 通过滑动窗口机制限制发送速率,接收方动态通告窗口大小(类似TCP)。 |
| 拥塞控制 | 避免网络过载 | 实现类似TCP的拥塞控制算法(如AIMD、BBR),根据丢包和延迟调整发送速率。 |
| 数据分片与重组 | 处理大数据传输 | 发送方将应用层数据分片为适合MTU的包,接收方根据序列号重组。 |
TSL四次握手
CA证书验证流程,存储在哪里?
常见攻击手段和预防手段
1. ddos攻击
| 攻击原理 | 常见手法 | 预防手段 |
|---|---|---|
| 通过海量恶意流量耗尽目标服务器资源,导致服务不可用。 | - 流量型攻击(如UDP Flood、ICMP Flood) - 协议型攻击(如SYN Flood、ACK Flood) - 应用层攻击(如HTTP Flood) | - 流量清洗:使用CDN或云防护服务(如Cloudflare、AWS Shield)过滤异常流量。 - 限速与黑名单:通过防火墙或Nginx限速(limit_req)。 - 协议优化:配置服务器抵御SYN Flood(如启用SYN Cookies)。 - 负载均衡:分散流量至多台服务器。 |
2. SQL注入
| 攻击原理 | 常见手法 | 预防手段 |
|---|---|---|
| 通过注入恶意SQL代码,篡改数据库查询逻辑。 | - 联合查询注入(UNION SELECT) - 布尔盲注 - 时间盲注 - 报错注入 |
- 参数化查询:使用预编译语句(如Java的PreparedStatement)。 - ORM框架:如Hibernate、SQLAlchemy,避免直接拼接SQL。 - 输入过滤:对特殊字符(如'、;)进行转义或白名单验证。 - 最小权限原则:数据库账户仅授予必要权限。 |
3. CSRF攻击
| 攻击原理 | 常见手法 | 预防手段 |
|---|---|---|
| 诱导用户执行非预期的跨站请求(如转账、改密)。 | - 伪造GET请求(通过图片链接) - 伪造POST表单(通过隐藏表单) | - CSRF Token:服务端生成随机Token,嵌入表单或请求头,验证请求来源。 - SameSite Cookie属性:设置为Strict或Lax(防止跨域携带Cookie)。 - 检查Referer头:验证请求来源域名是否合法。 |
4. XSS攻击
| 攻击原理 | 常见手法 | 预防手段 |
|---|---|---|
| 注入恶意脚本到网页中,窃取用户数据或会话。 | - 存储型XSS(恶意脚本存入数据库) - 反射型XSS(通过URL参数反射脚本) - DOM型XSS(客户端DOM操作触发) | - 输入输出过滤:对用户输入进行HTML实体转义(如<转义为<)。 - Content Security Policy (CSP):限制脚本来源(如script-src 'self')。 - HttpOnly Cookie:防止JavaScript窃取会话Cookie。 |
Socket有哪些了解(wxg,快手都问了)
我对 Socket 编程有比较深入的了解,它是在网络编程中实现进程间通信(特别是跨网络通信)的基础技术。以下是我对 Socket 编程关键方面的理解:
-
**核心概念与作用:**
- **Socket 的本质:** 是由操作系统提供的一种编程接口(API),是应用层与传输层之间的抽象层。它允许应用程序通过网络发送和接收数据。
- **通信端点:** 每个 Socket 代表网络通信的一个端点,由
IP地址 + 端口号唯一标识。 - **类比:** 类似于电话插座(Socket)和电话机(应用程序),插座提供了连接网络的物理/逻辑接口。
-
**关键模型:TCP vs UDP:**
- TCP (SOCK_STREAM):
- **面向连接:** 通信前需要建立连接(三次握手)。
- **可靠传输:** 保证数据顺序、无差错、不丢失、不重复地到达。
- **流式传输:** 数据被视为字节流,没有明确边界。应用程序需要自己处理消息边界(如添加长度前缀或分隔符)。
- **适用场景:** 需要高可靠性的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP)、电子邮件 (SMTP/POP3/IMAP)、数据库连接。
- UDP (SOCK_DGRAM):
- **无连接:** 无需建立连接,直接发送数据报。
- **不可靠传输:** 不保证数据一定到达、到达顺序、不丢失、不重复。可能丢包、乱序。
- **数据报传输:** 数据以独立的数据包(Datagram)为单位传输,有明确边界。
- **高效、低延迟:** 由于开销小,通常比 TCP 更快、延迟更低。
- **适用场景:** 实时性要求高、能容忍少量丢包的应用,如视频/音频直播、在线游戏、DNS 查询、广播/多播应用(如 DHCP)。
- TCP (SOCK_STREAM):
-
**核心编程步骤(以 TCP 服务器为例):**
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# 伪代码示意核心步骤 # 1. 创建服务器端 Socket (TCP) server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # AF_INET 指 IPv4 # 2. 绑定 Socket 到地址和端口 server_socket.bind(('0.0.0.0', 8080)) # 监听所有网络接口的 8080 端口 # 3. 开始监听连接请求 (TCP特有) server_socket.listen(5) # 设置等待连接队列的最大长度 # 4. 接受客户端连接 (阻塞直到有连接进来) client_socket, client_address = server_socket.accept() # 5. 与客户端通信 (接收/发送数据) data = client_socket.recv(1024) # 接收最多 1024 字节 client_socket.send(b'Hello Client!') # 发送数据 (注意字节串) # 6. 关闭连接 client_socket.close() # 7. (可选) 回到步骤4接收新连接 或 关闭服务器Socket server_socket.close() -
**核心编程步骤(以 TCP 客户端为例):**
1 2 3 4 5 6 7 8 9 10# 伪代码示意核心步骤 # 1. 创建客户端 Socket (TCP) client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2. 连接到服务器 (TCP特有) client_socket.connect(('server_ip', 8080)) # 替换为实际服务器IP和端口 # 3. 与服务器通信 (发送/接收数据) client_socket.send(b'Hello Server!') data = client_socket.recv(1024) # 4. 关闭连接 client_socket.close() -
**关键技术与概念:**
- **地址族:**
AF_INET(IPv4),AF_INET6(IPv6),AF_UNIX(本地 Unix 域套接字)。 - **套接字类型:**
SOCK_STREAM(TCP),SOCK_DGRAM(UDP),SOCK_RAW(原始套接字)。 - 阻塞 vs 非阻塞:
- **阻塞:** 调用
accept(),connect(),recv(),send()等函数时,程序会暂停执行,直到操作完成(如连接建立、数据到达)。 - **非阻塞:** 这些函数会立即返回,无论操作是否完成。需要使用
select,poll,epoll(Linux),kqueue(BSD/macOS) 或异步 I/O 模型(如asyncio)来高效管理多个 Socket。
- **阻塞:** 调用
- **I/O 多路复用:**
select,poll,epoll,kqueue等技术,允许一个进程/线程同时监视多个 Socket 的状态(是否可读、可写、有异常),提高并发性能。 - **字节序:** 网络字节序是大端序。需要使用
htonl(),htons(),ntohl(),ntohs()等函数在主机字节序和网络字节序之间转换数据(尤其是多字节整数和端口号)。 - **粘包/拆包:** TCP 流式传输的特性导致发送方多次发送的数据可能在接收方缓冲区中被合并成一个数据块(粘包),或者一个数据块被拆分成多次接收(拆包)。应用程序需要设计协议(如固定长度、长度前缀、分隔符)来处理边界。
- **错误处理:** 网络通信异常丰富(连接超时、中断、对端关闭、资源不足等),健壮的 Socket 程序必须妥善处理各种错误和异常。
- **超时设置:** 可以为 Socket 操作设置超时时间 (
settimeout()),防止程序无限期阻塞。
- **地址族:**
-
**实际应用:**
- 几乎所有网络应用底层都使用 Socket:Web 服务器 (Nginx, Apache)、数据库 (MySQL, Redis)、消息队列 (RabbitMQ, Kafka)、FTP/SFTP 客户端/服务器、邮件客户端/服务器、即时通讯软件、网络游戏、自定义协议的分布式系统通信等。
场景题
如何利用线程池去实现一个比如整点进行日志记录功能
【美团面试没做出来血的教训】
三个服务器如何进行负载均衡,让同一内容的请求打到同一台副本上,以及如何动态扩容在不影响前面三台机器的前提下
【百度面试没做出来血的教训】
了解一下一致性hash算法
提前预估出1000个哈希桶,然后进行划分(也就是做好提前量)
如何用redis筛选出前100名的排行榜,也就是动态更新redis,同时用户非常多,redis中放不下所有的
【快手面试没做出来血的教训】
操作系统
进程,线程和协程
最后是协程。协程是一种用户态的轻量级线程,其调度完全由用户程序控制,而不需要内核的参与。协程拥有自己的寄存器上下文和栈,但与其他协程共享堆内存。协程的切换开销非常小,因为只需要保存和恢复协程的上下文,而无需进行内核级的上下文切换。这使得协程在处理大量并发任务时具有非常高的效率。然而,协程需要程序员显式地进行调度和管理,相对于线程和进程来说,其编程模型更为复杂。
二、协程的核心优势
1. 轻量级并发
- 内存占用极低:协程栈大小通常为KB级(如Go的goroutine默认2KB)。
- 切换成本极低:协程切换在用户态完成(无需内核介入),单次切换耗时约100纳秒。
- 支持超高并发:单机可轻松创建数百万协程(如Go的goroutine)。
select、poll和epoll讲讲区别
核心对比表
IO复用技术
| 特性 | select | poll | epoll |
|---|---|---|---|
| 时间复杂度 | O(n) - 每次轮询所有fd | O(n) - 每次轮询所有fd | O(1) - 只处理就绪事件 |
| 最大文件描述符 | 有限制 (通常1024) | 无硬性限制 | 无硬性限制 |
| 工作方式 | 轮询所有文件描述符 | 轮询所有文件描述符 | 回调通知机制 |
| 内核数据结构 | 位图 (fd_set) | 链表 (pollfd) | 红黑树+就绪链表 |
| 触发模式 | 仅支持水平触发 (LT) | 仅支持水平触发 (LT) | 支持水平触发 (LT) + 边缘触发 (ET) |
| 内存拷贝开销 | 每次调用需复制整个fd_set | 每次调用需复制整个pollfd数组 | 注册时一次拷贝 |
| 适用场景 | 低并发/跨平台场景 | 需要更多fd但并发不高 | 高并发场景 (>1000连接) |
| API复杂度 | 简单 | 较简单 | 较复杂 |
| 跨平台性 | 广泛支持 | POSIX标准 | Linux特有 |
内核态与用户态
操作系统中进程死锁条件(那四个),如何死锁避免,死锁检测
死锁的四个必要条件(必须同时存在才会死锁)
| 条件 | 说明 |
|---|---|
| 1. 互斥 | 资源一次只能被一个进程独占(如打印机) |
| 2. 占有并等待 | 进程已持有资源,同时请求新资源且不释放已有资源 |
| 3. 不可抢占 | 资源只能由持有者主动释放,不可强行剥夺 |
| 4. 循环等待 | 进程间形成环形等待链:P1等P2的资源,P2等P3的资源… Pn等P1的资源 |
死锁避免策略(预防死锁发生)
- 资源分配策略
- 银行家算法:进程申请资源时,预判分配后系统是否仍处于安全状态(即存在安全序列)
- 若不安全则拒绝分配(即使当前资源足够)
- 资源有序分配法:为所有资源类型定义全局顺序,进程必须按序申请资源(如只能先申请A再申请B)
- 银行家算法:进程申请资源时,预判分配后系统是否仍处于安全状态(即存在安全序列)
- 进程启动控制
- 新进程启动时检查其最大资源需求,若可能引发不安全状态则延迟启动
死锁检测方法(发生后识别)
- 资源分配图(RAG)检测
- 顶点:进程(P) + 资源类型(R)
- 边:
- 请求边 P → R(进程等待资源)
- 分配边 R → P(资源已被进程占用)
- 检测循环:使用图算法(如DFS)检查图中是否存在闭环 → 存在环即死锁
- 检测时机
- 定时检测(如每5分钟)
- 当CPU利用率骤降时触发检测
死锁恢复手段(检测到后处理)
| 方法 | 操作 |
|---|---|
| 进程终止 | 强制终止所有死锁进程(简单粗暴)或按优先级逐步终止进程直到死锁解除 |
| 资源抢占 | 强制回收某个进程的资源(需解决被抢占进程的后续恢复问题,如回滚操作) |
MySQL
SQL基础
数据库三大范式是什么
好的!数据库的三大范式(Normalization)是关系型数据库设计的核心原则,目的是减少数据冗余、提高数据一致性。我用生活中的例子帮你轻松理解,保证不枯燥!
先看一个“反面教材”表格
假设设计一个「学生课程表」,直接存成这样:
| 学号 | 姓名 | 课程 | 学分 | 教师 | 教师办公室 |
|---|---|---|---|---|---|
| 1001 | 张三 | 数学,英语 | 4,3 | 王老师 | A栋301, B栋202 |
| 1002 | 李四 | 物理 | 2 | 张老师 | C栋105 |
问题:
- 数据冗余:同一门课程的教师和办公室被重复存储。
- 更新异常:如果“王老师”换办公室,所有相关行都要改。
- 插入异常:新教师没安排课程时,无法录入信息。
- 删除异常:删除某门课程可能连带删除教师信息。
第一范式(1NF)——原子性
核心要求:每列的值必须是不可再分的最小数据单元(原子性)。 问题:上表中“课程”、“学分”、“教师”、“教师办公室”包含多个值。 解决方案:拆分为单值:
| 学号 | 姓名 | 课程 | 学分 | 教师 | 教师办公室 |
|---|---|---|---|---|---|
| 1001 | 张三 | 数学 | 4 | 王老师 | A栋301 |
| 1001 | 张三 | 英语 | 3 | 李老师 | B栋202 |
| 1002 | 李四 | 物理 | 2 | 张老师 | C栋105 |
关键点:
- 每行数据描述一个独立实体(比如一门课程)。
- 但仍有冗余(如“张老师”的信息重复)。
第二范式(2NF)——消除部分依赖
核心要求:表中每个字段必须完全依赖主键(不能只依赖主键的一部分)。 前提:表必须有复合主键(多个字段共同作为主键)。
分析上表:
- 主键是(学号, 课程),因为需要这两个字段唯一标识一行。
- 问题:
- “姓名”只依赖学号(与课程无关)→ 部分依赖。
- “教师”和“教师办公室”只依赖课程(与学号无关)→ 部分依赖。
解决方案:拆分为三张表!
-
学生表(主键:学号):
学号 姓名 1001 张三 1002 李四 -
课程表(主键:课程):
课程 学分 教师 教师办公室 数学 4 王老师 A栋301 英语 3 李老师 B栋202 物理 2 张老师 C栋105 -
选课表(主键:学号+课程):
学号 课程 1001 数学 1001 英语 1002 物理
关键点:
- 每张表只描述一件事(学生、课程、选课关系)。
- 冗余消除:教师信息只存一次,修改时只需改一处。
第三范式(3NF)——消除传递依赖
核心要求:表中字段不能依赖其他非主键字段(即避免“间接依赖”)。
分析课程表:
- 主键是“课程”。
- “教师办公室”依赖“教师”(教师 → 教师办公室),而“教师”依赖主键“课程”。
- 存在传递依赖:课程 → 教师 → 教师办公室。
问题:
- 如果“王老师”换办公室,需修改所有他教授的课程对应的行。
解决方案:继续拆分!
-
教师表(主键:教师):
教师 教师办公室 王老师 A栋301 李老师 B栋202 张老师 C栋105 -
课程表(主键:课程):
课程 学分 教师 数学 4 王老师 英语 3 李老师 物理 2 张老师
关键点:
- 教师办公室信息只与教师相关,和课程无关。
- 修改教师办公室时,只需改“教师表”中的一行。
总结:三大范式的作用
| 范式 | 核心要求 | 解决的问题 |
|---|---|---|
| 1NF | 数据原子性 | 字段不可再分(如拆分多值字段) |
| 2NF | 消除部分依赖 | 拆分依赖复合主键的部分字段 |
| 3NF | 消除传递依赖 | 拆分间接依赖的非主键字段 |
1. 减少数据冗余
-
问题:如果数据重复存储(如学生表中每个课程都重复学生姓名),会浪费存储空间,且容易导致数据不一致。
-
解决:通过拆分表(如学生表、课程表、选课表),每个信息只存一次。
1 2 3 4 5 6 7 8 9 10 11 12-- 反例:冗余存储学生姓名和课程信息 CREATE TABLE bad_design ( student_id INT, student_name VARCHAR(50), course_name VARCHAR(50), teacher VARCHAR(50) ); -- 遵循范式:拆分为多表 CREATE TABLE students (student_id INT PRIMARY KEY, student_name VARCHAR(50)); CREATE TABLE courses (course_id INT PRIMARY KEY, course_name VARCHAR(50), teacher VARCHAR(50)); CREATE TABLE enrollments (student_id INT, course_id INT);
2. 避免更新异常
-
问题:冗余数据会导致修改时多处同步。
- 例如,如果“王老师”的办公室地址在多个课程行中重复存储,修改时漏掉某一行会导致数据不一致。
-
解决:通过范式拆分后,只需在「教师表」中修改一次。
1 2 3 4 5-- 反范式设计(修改麻烦) UPDATE courses SET teacher_office = 'A栋302' WHERE teacher = '王老师'; -- 范式设计(只需改一处) UPDATE teachers SET office = 'A栋302' WHERE teacher_name = '王老师';
3. 消除插入和删除异常
-
问题:
- 插入异常:无法单独插入未分配课程的教师信息。
- 删除异常:删除某门课程可能连带删除教师信息。
-
解决:拆分表后,教师和课程独立存在。
1 2 3 4 5-- 插入异常示例(反范式): -- 如果“新教师”未授课,无法插入到课程表中。 -- 范式设计下: INSERT INTO teachers (teacher_name, office) VALUES ('赵老师', 'D栋101'); -- 允许独立插入
4. 提高数据一致性
-
问题:冗余数据可能导致矛盾(如某个课程的学分在不同行中不一致)。
-
解决:通过范式设计,学分只存储在「课程表」中,所有引用该课程的地方通过外键关联,确保一致性。
1 2 3 4 5 6-- 反范式设计(学分可能不一致) INSERT INTO bad_table (course_name, credit) VALUES ('数学', 4); INSERT INTO bad_table (course_name, credit) VALUES ('数学', 5); -- 矛盾! -- 范式设计(学分唯一): CREATE TABLE courses (course_id INT PRIMARY KEY, credit INT);
5. 增强可维护性
-
问题:当业务需求变化时(如新增字段),冗余的表结构修改成本高。
-
解决:范式设计后,表结构清晰,修改只需调整局部。
1 2 3-- 反范式设计:新增“课程类型”字段需修改所有相关行。 -- 范式设计:只需在「课程表」中加一列。 ALTER TABLE courses ADD COLUMN course_type VARCHAR(20);
MySQL 怎么连表查询?
数据库有以下几种联表查询类型:
- 内连接(INNERJOIN)
- 左外连接(LEFTJOIN)
- 右外连接(RIGHTJOIN)
- 全外连接(FULLJOIN)
讲讲ACID
这四个特性分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation) 和持久性(Durability)。
存储引擎
讲一讲mysql的引擎吧,你有什么了解?
-
InnoDB:InnoDB是MySQL的默认存储引l擎,具有ACID事务支持、行级锁、外键约束等特性。它适用于 高并发的读写操作,支持较好的数据完整性和并发控制。
-
MyISAM:MyISAM是MySQL的另一种常见的存储引擎,具有较低的存储空间和内存消耗,适用于大量 读操作的场景。然而,MyISAM不支持事务、行级锁和外键约束,因此在并发写入和数据完整性方面有 一定的限制。
-
Memory:Memory引l擎将数据存储在内存中,适用于对性能要求较高的读操作,但是在服务器重启或 崩溃时数据会丢失。它不支持事务、行级锁和外键约束。
索引
索引有哪些优化手段,讲一下B+树索引
常见优化索引|的方法:
-
前缀索引优化:使用前缀索引是为了减小索引字段大小,可以增加一个索引顶中存储的索引值,有效提 高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大 小。
-
覆盖索引I优化:覆盖索引是指SQL中query的所有字段,在索引|B+Tree的叶子节点上都能找得到的那 些索引,从二级索引中查询得到记录,而不需要通过聚簇索引查询获得,可以避免回表的操作。
-
主键索引最好是自增的:
○ 如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移 动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操 作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
○ 如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就 可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需 要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成 大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
-
防止索引失效:
○ 当我们使用左或者左右模糊匹配的时候,也就是
like%xx或者like%xx%这两种方式都会造成索 引失效; ○ 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效; ○ 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则 就会导致索引失效。 ○ 在WHERE子句中,如果在OR前的条件列是索引列,而在OR后的条件列不是索引I列,那么索引会 失效。
如果给每一列都建立一个索引会有什么问题?
空间占用多,然后写入频繁场景,因为索引要被更新,所以维护B+树付出的性能消耗也大
事务
隔离级别
| 隔离级别 | 解决的并发问题 |
|---|---|
| 读未提交 | |
| 读提交 | 脏读 |
| 可重复读 | 不可重复读 |
| 串行化 | 幻读 |
mvcc解释一下
多版本并发控制
锁
讲一下mysql里有哪些锁?
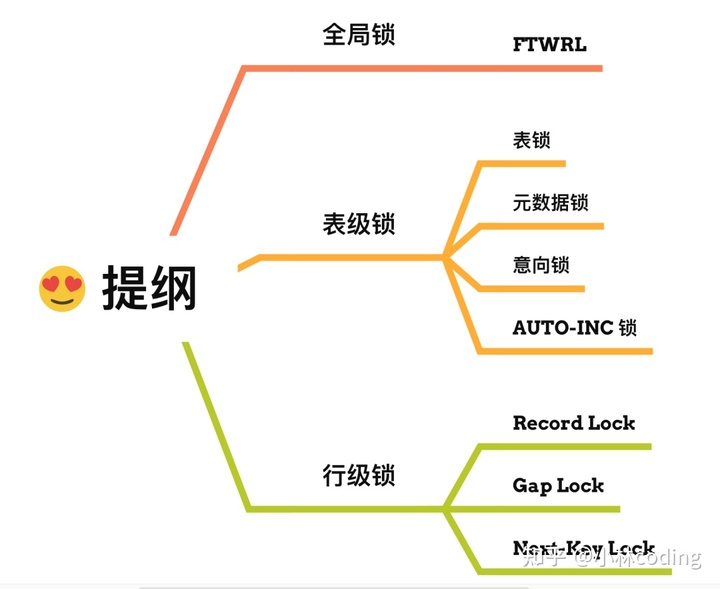
- 行级锁:InnoDB引擎是支持行级锁的,而MyISAM引擎并不支持行级锁。
- 记录锁,锁住的是一条记录。而且记录锁是有S锁和X锁之分的,满足读写互斥,写写互斥
- 间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
- Next-KeyLock称为临键锁,是Record Lock+GapLock的组合,锁定一个范围,并且锁定记录本身。
性能调优
慢sql优化
- 分析查询语句:使用EXPLAIN命令分析SQL执行计划,找出慢查询的原因,比如是否使用了全表扫描,是否存在索引未被利用的情况等,并根据相应情况对索引进行适当修改。
- 创建或优化索引:根据查询条件创建合适的索引I,特别是经常用于WHERE子句的字段、Orderby排序的字段、Join连表查询的字典、groupby的字段,并且如果查询中经常涉及多个字段,考虑创建联合索引,使用联合索引要符合最左匹配原则,不然会索引失效
- **避免索引失效:**比如不要用左模糊匹配、函数计算、表达式计算等等。
- 查询优化:避免使用SELECT,只查询真正需要的列;使用覆盖索引I,即索引I包含所有查询的字段;联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。
- **分页优化:**针对limit n,y深分页的查询优化,可以把Limit查询转换成某个位置的查询:selectfrom tb_skuwhere id>20000 limit 10,该方案适用于主键自增的表,
- 优化数据库表:如果单表的数据超过了干万级别,考虑是否需要将大表拆分为小表,减轻单个表的查询压力。也可以将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开。
- 使用缓存技术:引入缓存层,如Redis,存储热点数据和频繁查询的结果,但是要考虑缓存一致性的问题,对于读请求会选择旁路缓存策略,对于写请求会选择先更新db,再删除缓存的策略。
Java基础
final关键字用法
1. final修饰变量
基本类型变量
- 被final修饰的基本类型变量一旦初始化就不能被修改
- 必须在声明时或构造函数中初始化
|
|
引用类型变量
- 引用不能改变,但对象内部状态可以改变
|
|
2. final修饰方法
- 被final修饰的方法不能被子类重写
- 常用于防止子类改变方法的行为
|
|
3. final修饰类
- 被final修饰的类不能被继承
- 常用于设计不希望被扩展的类
|
|
4. final参数
- 方法参数被final修饰后,方法内不能修改该参数
|
|
5. final与并发编程
- final变量在多线程环境下是线程安全的,不需要额外的同步措施
- JVM保证final变量的初始化安全
讲解HashMap扩容
在JDK1.7版本之前,HashMap数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
所以在JDK1.8版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(logn),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
hashMap默认的负载因子是0.75,即如果hashmap中的元素个数超过了总容量75%,则会触发扩容,扩容 分为两个步骤:
- 第1步是对哈希表长度的扩展(2倍)
- 第2步是将旧哈希表中的数据放到新的哈希表中。
垃圾回收策略
- 标记-清除算法:标记-清除算法分为”标记”和“清除”两个阶段,首先通过可达性分析,标记出所有需要回收的对象,然后统一回收所有被标记的对象。标记-清除算法有两个缺陷,一个是效率问题,标记和清除的过程效率都不高,另外一个就是,清除结束后会造成大量的碎片空间。有可能会造成在申请大块内存的时候因为没有足够的连续空间导致再次GC。
- 复制算法:为了解决碎片空间的问题,出现了“复制算法”。复制算法的原理是,将内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上。然后将然后再把已使用的内存整个清理掉。复制算法解决了空间碎片的问题。但是也带来了新的问题。因为每次在申请内存时,都只能使用一半的内存空间。内存利用率严重不足。
- 标记-整理算法:复制算法在GC之后存活对象较少的情况下效率比较高,但如果存活对象比较多时,会执行较多的复制操作,效率就会下降。而老年代的对象在GC之后的存活率就比较高,所以就有人提出了“标记-整理算法”。标记-整理算法的“标记”过程与”标记-清除算法”的标记过程一致,但标记之后不会直接清理。而是将所有存活对象都移动到内存的一端。移动结束后直接清理掉剩余部分。
- 分代回收算法:分代收集是将内存划分成了新生代和老年代。分配的依据是对象的生存周期,或者说经历过的GC次数。对象创建时,一般在新生代申请内存,当经历一次GC之后如果对还存活,那么对象的年龄+1。当年龄超过一定值(默认是15,可以通过参数-XX:MaxTenuringThreshold来设定)后,如果对象还存活,那么该对象会进入老年代。
讲讲Spring
Spring有两个核心模块:IoC和AOP
IoC:控制反转,通过 依赖查找(DL) 和 依赖注入(DI) 实现的。指的是将创建的对象交给Spring进行管理。
- 应用启动时,Spring会创建所有需要管理的对象(称为Bean)并放入IoC容器
- 开发者通过注解定义对象的创建规则,而非手动
new实例 - 对象之间的依赖关系由Spring自动处理
AOP:面向切面编程,通过动态代理技术实现,能够在不修改原有代码的情况下,为程序横向添加通用功能(如日志、事务、权限等)。
讲讲线程池原理
在实际项目中,线程池是我最常用的并发编程工具之一。以下是我使用线程池的经验和最佳实践:
1. 线程池的创建
我通常使用ThreadPoolExecutor来创建线程池,而不是直接使用Executors的工厂方法,因为这样可以更灵活地控制参数:
|
|
2. 参数配置经验
- 核心线程数:通常设置为CPU核心数的1-2倍(CPU密集型任务)或更多(IO密集型任务)
- 最大线程数:IO密集型可设置较高(如核心数的2-4倍),CPU密集型不宜过高
- 队列容量:根据业务特点设置,高吞吐场景用大队列,低延迟场景用小队列
- 拒绝策略:根据业务需求选择或自定义(记录日志、降级处理等)
讲讲讲一下threadlocal的原理,threadlocal存在的问题?
如果两个服务需要传递threadlocal中的值例如用户ID该如何传递
你知道哪些JVM的垃圾回收器
- Serial收集器(复制算法): 新生代单线程收集器,标记和清理都是单线程,优点是简单高效;
- Parallel GC(并行垃圾回收器):
- G1(Garbage First)收集器 (标记-整理算法)
Java的类加载机制是怎么样的
-
加载(Loading)
-
通过类的全限定名获取二进制字节流
-
将字节流转换为方法区的运行时数据结构
-
在堆中生成代表该类的Class对象
-
-
验证(Verification)
-
文件格式验证(魔数、版本号等)
-
元数据验证(语义分析)
-
字节码验证(确保方法不会危害JVM)
-
符号引用验证(确保解析能正确执行)
-
-
准备(Preparation)
-
为类变量(static变量)分配内存并设置初始值(零值)
-
注意:final static变量在此阶段直接赋值为代码中的值
-
-
解析(Resolution)
- 将常量池内的符号引用替换为直接引用
-
初始化(Initialization)
-
执行类构造器
<clinit>()方法(包含static变量赋值和static代码块) -
父类的
<clinit>先于子类执行
-
讲讲AQS
可重入锁是指同一个线程在获取了锁之后,可以再次重复获取该锁而不会造成死锁或其他问题。当一个线 程持有锁时,如果再次尝试获取该锁,就会成功获取而不会被阻塞。 ReentrantLock实现可重入锁的机制是基于线程持有锁的计数器。 ·当一个线程第一次获取锁时,计数器会加1,表示该线程持有了锁。在此之后,如果同一个线程再次获 取锁,计数器会再次加1。每次线程成功获取锁时,都会将计数器加1。 ·当线程释放锁时,计数器会相应地减1。只有当计数器减到0时,锁才会完全释放,其他线程才有机会 获取锁。 这种计数器的设计使得同一个线程可以多次获取同一个锁,而不会造成死锁或其他问题。每次获取锁时, 计数器加1;每次释放锁时,计数器减1。只有当计数器减到0时,锁才会完全释放。 ReentrantLock通过这种计数器的方式,实现了可重入锁的机制。它允许同一个线程多次获取同一个锁, 并且能够正确地处理锁的获取和释放,避免了死锁和其他并发问题。
讲讲内存区域
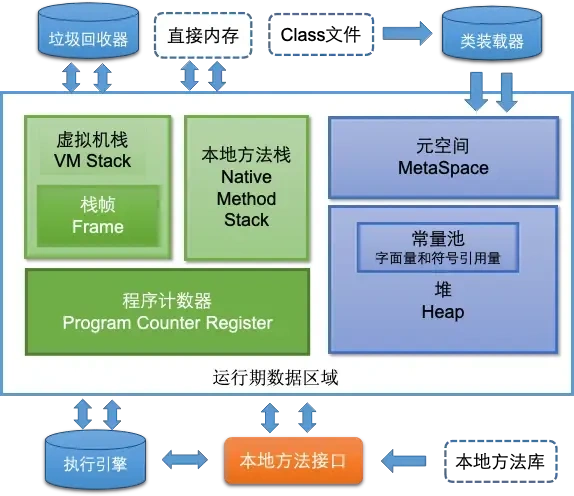
静态变量放哪,不同进程压栈在一个共用栈还是私有栈?
私有栈
Redis
redis了解过吗,有哪些应用?
Redis(Remote Dictionary Server)是一款高性能的内存数据库,支持多种数据结构,常用于解决高并发、低延迟场景下的数据管理问题。以下是其核心特性及典型应用场景:
一、Redis的核心优势
- 内存存储:数据读写速度达微秒级(10万+ QPS),远超传统磁盘数据库。
- 丰富的数据结构:支持字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(ZSet)、流(Stream)等,覆盖多样化场景。
- 持久化机制:通过RDB快照和AOF日志实现数据持久化,保障宕机后数据可恢复。
- 高可用性:支持主从复制、哨兵(Sentinel)、集群(Cluster)模式,满足高可用需求。
二、Redis的6大典型应用场景
**1. 缓存(Cache)**
-
问题:数据库读写速度慢,无法应对高并发请求。
-
方案:将热点数据(如商品详情、用户信息)缓存到Redis,降低数据库负载。
-
实现:
1 2 3 4bashCopy Code# 设置缓存(带30分钟过期时间) SET product:1001 "{name: 'Phone', price: 5999}" EX 1800 # 查询缓存 GET product:1001 -
优化技巧:
- 缓存穿透:布隆过滤器(Bloom Filter)拦截无效请求。
- 缓存雪崩:随机化过期时间,避免集中失效。
**2. 会话存储(Session Storage)**
-
问题:分布式系统中用户会话需跨服务共享。
-
方案:用Redis集中存储会话数据(如登录状态、购物车)。
-
实现:
1 2 3 4bashCopy Code# 存储用户会话 HSET session:user123 token "abc123" cart "[{id: 1, count: 2}]" # 设置30分钟过期 EXPIRE session:user123 1800
3. 排行榜与计数器
-
问题:实时更新排名(如游戏积分榜、热搜词)。
-
方案:利用有序集合(ZSet)按分数排序。
-
实现:
1 2 3 4bashCopy Code# 添加玩家得分 ZADD leaderboard 5000 "player1" 4800 "player2" # 获取前10名 ZREVRANGE leaderboard 0 9 WITHSCORES
4. 消息队列
-
问题:服务间异步通信需求(如订单支付后通知物流)。
-
方案:使用列表(List)或Stream实现轻量级队列。
-
实现(List):
1 2 3 4bashCopy Code# 生产者推送消息 LPUSH order:queue "order1001" # 消费者阻塞获取 BRPOP order:queue 30 -
高级场景:Stream支持消费者组(Consumer Group),类似Kafka的分区消费。
5. 分布式锁
-
问题:多实例服务竞争资源时需互斥访问(如秒杀扣库存)。
-
方案:通过
SETNX或RedLock实现分布式锁。 -
实现(SETNX):
1 2 3 4bashCopy Code# 加锁(设置唯一值防误删) SET lock:stock 1 NX EX 10 # 释放锁(Lua脚本保证原子性) EVAL "if redis.call('get', KEYS) == ARGV then return redis.call('del', KEYS) else return 0 end" 1 lock:stock 1
6. 实时数据分析
-
问题:高频数据实时统计(如在线人数、UV/PV)。
-
方案:通过HyperLogLog统计基数,Bitmap记录用户行为。
-
实现:
1 2 3 4 5 6bashCopy Code# HyperLogLog统计UV(误差率0.81%) PFADD uv:20231001 user1 user2 user3 PFCOUNT uv:20231001 # Bitmap记录用户签到 SETBIT sign:user123:202310 5 1 # 第5天签到 BITCOUNT sign:user123:202310 # 当月签到次数
三、Redis vs 其他技术选型对比
| 场景 | Redis优势 | 替代方案 |
|---|---|---|
| 缓存 | 数据结构灵活,支持过期时间、持久化 | Memcached(纯缓存,无持久化) |
| 消息队列 | 轻量级,支持Stream的消费者组 | Kafka/RabbitMQ(高吞吐) |
| 分布式锁 | 原子操作简单易用 | ZooKeeper(强一致性) |
| 实时统计 | HyperLogLog节省内存,适合大数据量 | Flink/Spark(复杂计算) |
四、Redis的局限性
- 内存成本高:数据量过大时需权衡成本(如冷数据归档到磁盘库)。
- 持久化性能损耗:AOF的
fsync always模式会降低吞吐量。 - 事务非强一致:Redis事务不支持回滚(通过Lua脚本弥补)。
总结
Redis凭借内存速度和数据结构多样性,成为高并发系统的核心组件,适用于缓存、会话管理、实时排行榜等场景。实际应用中需结合业务特点选择数据结构,并合理设计过期策略、持久化配置及高可用方案(如集群部署)。
redis常用数据结构
1. 字符串(String)
-
底层实现:简单动态字符串(SDS, Simple Dynamic String)
-
特点:
- 预分配内存空间,减少修改时的内存重分配次数。
- 二进制安全(可存储任意二进制数据,如
\0)。 - 直接存储长度(
O(1)复杂度获取长度)。
-
结构体:
1 2 3 4 5struct sdshdr { int len; // 已用长度 int free; // 空闲空间 char buf[]; // 字符数组 };
-
2. 列表(List)
- 底层实现:QuickList(Redis 3.2+)
- 设计:双向链表 + 压缩列表(或 listpack)的混合结构。
- 特点:
- 每个节点是一个压缩列表(ziplist)或 listpack,平衡内存连续性和插入性能。
- 支持双向遍历,适合实现队列、栈等结构。
- 旧版本:小规模数据使用 ziplist,大规模数据使用 双向链表。
3. 哈希(Hash)
- 底层实现:
- 小规模数据:Listpack(Redis 7.0+)或 ziplist(旧版本)。
- 大规模数据:哈希表(Dict),采用链式冲突解决和渐进式 Rehash。
- 转换条件:
hash-max-listpack-entries(默认 512):键值对数量阈值。hash-max-listpack-value(默认 64字节):单个值的最大字节。
4. 集合(Set)
- 底层实现:
- 纯整数且元素少:IntSet(整数数组,有序且紧凑)。
- 其他情况:哈希表(Dict),键为元素,值为
NULL。 - 转换条件:由
set-max-intset-entries控制(默认 $512$)。
5. 有序集合(ZSet)
- 底层实现:
- 小规模数据:Listpack(Redis $7.0$+)或 ziplist(旧版本),按分值排序。
- 大规模数据:跳表(SkipList) + 哈希表(Dict)。
- 跳表:支持
O(logN)范围查询(如ZRANGE)。 - 哈希表:存储
成员 -> 分值的映射,实现O(1)单元素查询。
- 跳表:支持
- 转换条件:
zset-max-listpack-entries(默认 $128$ ):元素数量阈值。zset-max-listpack-value(默认 $64$ 字节):成员最大长度。
6. 其他结构
- Streams:基数树(Rax Tree)实现消息队列,支持多播。
- HyperLogLog:稀疏和密集两种编码,用于基数统计。
- 位图(Bitmap):基于 SDS 字符串的位操作。
- 地理空间(GEO):使用 ZSet 存储 GeoHash 编码的位置。
redis的高可用性方案有哪些,具体讲一讲
1. 主从复制(Replication)
-
原理:
- 主节点(Master)处理写请求,并将数据异步复制到多个从节点(Slave)。
- 从节点默认只读,用于负载均衡读请求。
-
优点:
- 数据冗余:从节点提供数据备份。
- 读写分离:分担主节点的读压力。
-
缺点:
- 非高可用:主节点宕机后需手动切换到从节点。
- 异步复制:存在数据丢失风险(主节点宕机时未同步的数据会丢失)。
-
配置示例:
1 2# 在从节点配置文件中指定主节点 replicaof <master-ip> <master-port>
2. 哨兵模式(Sentinel)
-
原理:
- 哨兵(Sentinel) 是一个独立的进程集群,监控主从节点的健康状态。
- 当主节点不可用时,哨兵通过投票机制自动选举一个从节点升级为新主节点,并通知客户端和从节点更新配置。
-
核心功能:
- 监控:定期检测节点状态。
- 自动故障转移(Failover)。
- 配置中心:客户端通过哨兵获取当前主节点地址。
-
工作流程:
- 主观下线:单个哨兵认为主节点不可用。
- 客观下线:多个哨兵(满足
quorum数)确认主节点故障。 - 选举领导者哨兵:执行故障转移操作。
- 切换主节点:选择数据最新的从节点成为新主。
-
优点:
- 自动故障转移,无需人工干预。
- 支持多哨兵部署,避免单点故障。
-
缺点:
- 写操作单点:主节点仍是性能瓶颈。
- 扩展性有限:分片需客户端自行实现。
-
配置示例:
1 2 3# Sentinel 配置文件 sentinel monitor mymaster 127.0.0.1 6379 2 # 监控名为 mymaster 的主节点,2 表示至少 2 个哨兵确认故障 sentinel down-after-milliseconds mymaster 5000 # 5 秒无响应视为下线
3. Redis Cluster(集群模式)
-
原理:
- 数据分片:将数据按哈希槽(Hash Slot,共 16384 个)分配到多个主节点。
- 多主多从:每个主节点有 1 到多个从节点,主节点故障时从节点自动接替。
- Gossip 协议:节点间通过 P2P 通信同步状态和拓扑信息。
-
核心特性:
- 自动分片:客户端直连任意节点,由节点返回正确路由(MOVED/ASK 重定向)。
- 高可用:主节点故障时,从节点自动晋升为新主。
- 线性扩展:支持动态增删节点,哈希槽重新分配。
-
优点:
- 去中心化:无单点瓶颈。
- 高可用与高扩展性:适合大规模分布式场景。
-
缺点:
- 客户端兼容性:需支持 Cluster 协议的客户端(如 Jedis Cluster)。
- 功能限制:跨槽事务、多键操作受限(需使用 Hash Tag 保证 key 在同一槽)。
-
配置示例:
1 2 3 4# 启动集群节点 redis-server --cluster-enabled yes --cluster-config-file nodes.conf # 创建集群(3 主 3 从) redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 ... --cluster-replicas 1
缓存雪崩、击穿、穿透是什么?怎么解决?
在分布式系统中,缓存是提升性能和降低数据库压力的重要手段,但缓存使用不当可能导致雪崩、击穿、穿透三大经典问题。以下是它们的核心定义、原因及解决方案:
**1. 缓存雪崩(Cache Avalanche)**
定义
大量缓存数据在同一时间失效或者Redis故障宕机,导致所有请求直接穿透到数据库,引发数据库瞬时高负载甚至崩溃。 类比:多个水库同时决堤,洪水直接冲击下游村庄。
原因
- 缓存数据设置了相同的过期时间(例如批量预热缓存时未添加随机因子)。
- 缓存服务整体宕机(如 Redis 集群故障)。
解决方案
- 差异化过期时间
- 在缓存过期时间基础上添加随机值(例如
TTL = 基础时间 + 随机分钟),避免同时失效。
- 在缓存过期时间基础上添加随机值(例如
- 互斥锁重建缓存
- 当缓存失效时,使用分布式锁(如 Redis 的
SETNX)控制只有一个线程重建缓存,其他线程等待后重试。
- 当缓存失效时,使用分布式锁(如 Redis 的
- 熔断降级与限流
- 在数据库层面设置熔断机制(如 Hystrix),或使用限流工具(如 Sentinel)控制请求流量。
- 缓存集群高可用
- 使用 Redis Cluster 或哨兵模式(Sentinel)避免单点故障。
**2. 缓存击穿(Cache Breakdown)**
定义
某个热点数据过期后,大量并发请求同时穿透缓存,直接访问数据库。 类比:一颗子弹击穿防弹衣,所有攻击集中在一个点。
原因
- 热点数据过期(例如明星绯闻、秒杀商品信息)。
- 高并发请求集中在同一数据上。
解决方案
- 热点数据永不过期
- 缓存不设置过期时间,通过异步线程定期更新(例如每 10 分钟刷新一次)。
- 互斥锁重建缓存
- 类似缓存雪崩的解决方案,使用分布式锁避免多个线程同时重建缓存。
- 逻辑过期
- 缓存中存储数据的逻辑过期时间(例如字段
expire_time),业务层判断是否需异步更新。
- 缓存中存储数据的逻辑过期时间(例如字段
- 请求合并
- 将多个并发请求合并为一个数据加载任务(如本地队列或消息队列)。
**3. 缓存穿透(Cache Penetration)**
定义
查询不存在的数据(如非法 ID),绕过缓存直接访问数据库。 类比:攻击者绕过城墙,直接挖掘隧道攻击城内。
原因
- 恶意攻击或业务逻辑缺陷(例如频繁查询不存在的用户 ID)。
- 数据库和缓存均未存储该数据,导致每次请求都穿透到数据库。
解决方案
- 缓存空值(Null Cache)
- 对查询结果为空的请求,缓存一个短时间空值(例如
key: -1, TTL=5 分钟)。
- 对查询结果为空的请求,缓存一个短时间空值(例如
- 布隆过滤器(Bloom Filter)
- 在缓存层前添加布隆过滤器,快速判断数据是否存在:
- 若布隆过滤器判定数据不存在,直接返回空结果。
- 若判定存在,再查询缓存或数据库。
- 在缓存层前添加布隆过滤器,快速判断数据是否存在:
- 接口校验与限流
- 对请求参数进行合法性校验(如 ID 必须为数字),拦截非法请求。
- 对高频 IP 或用户进行限流或黑名单拦截。
- 实时监控与防御
- 监控数据库慢查询日志,识别异常请求模式(如大量
404请求)。
- 监控数据库慢查询日志,识别异常请求模式(如大量
三者的核心区别
| 问题类型 | 触发条件 | 影响范围 | 典型场景 |
|---|---|---|---|
| 缓存雪崩 | 大量缓存同时失效 | 全局性数据库压力 | 批量缓存预热、缓存集群宕机 |
| 缓存击穿 | 单个热点数据失效 | 单点数据库压力 | 秒杀商品、热点新闻 |
| 缓存穿透 | 查询不存在的数据 | 无效请求消耗资源 | 恶意攻击、参数伪造 |
实战案例
- 电商秒杀场景
- 雪崩:秒杀开始时所有商品缓存同时失效 → 使用随机 TTL + 互斥锁。
- 击穿:某热门商品缓存过期 → 逻辑过期 + 请求合并。
- 穿透:恶意刷不存在的商品 ID → 布隆过滤器 + 空值缓存。
- 社交网络热点事件
- 明星热搜数据缓存失效 → 永不过期 + 异步更新。
大key是什么意思呢?怎么解决
Zset的底层数据结构
Redis 的 ZSet 为何选择跳表(Skip List)而非红黑树?
Redis 的有序集合(ZSet)底层默认使用 跳表(Skip List) 和 哈希表 的组合实现(当元素较少或成员是长字符串时,可能使用压缩列表)。选择跳表而非红黑树,主要基于以下几点原因:
1. 查询性能的权衡
- 跳表的查询复杂度:平均 O(logn)O(logn),最坏 O(n)O(n)(但概率极低,通过合理的随机层数控制可避免)。
- 红黑树的查询复杂度:严格 O(logn)O(logn)。
虽然两者在理论上都是对数级别,但跳表的实际查询效率接近红黑树,且实现更简单。
2. 插入和删除操作的效率
- 跳表的插入/删除:
- 平均 O(logn)O(logn),仅需局部调整相邻节点的指针。
- 无需复杂的再平衡(红黑树需要旋转和变色)。
- 红黑树的插入/删除:
- 虽然也是 O(logn)O(logn),但需要处理复杂的平衡逻辑(旋转和变色),代码实现更复杂。
跳表的优势:在高并发场景下,跳表的局部修改特性更容易实现无锁优化(Redis 6.0 的多线程 I/O 对命令处理仍是单线程,但跳表为未来可能的扩展留了余地)。
3. 范围查询的高效性
- 跳表:天然支持有序遍历,范围查询(如
ZRANGE)只需遍历链表,时间复杂度 O(logn+m)O(logn+m)(mm 为返回的元素数量)。 - 红黑树:范围查询需要中序遍历,实现较复杂,且缓存局部性不如跳表。
Redis 的场景需求:ZSet 常用于排行榜、区间查询(如分数范围),跳表的顺序访问特性更契合。
4. 实现复杂度
- 跳表:实现简单,约 200 行代码即可完成核心逻辑,调试和维护成本低。
- 红黑树:实现复杂,需处理多种旋转和变色情况,容易出错。
Redis 的设计哲学:优先选择简单、高效的数据结构,跳表在性能和实现复杂度之间取得了更好的平衡。
5. 内存占用
- 跳表:通过随机层数(通常概率为 1/21/2),平均每个节点只需 1.33 个额外指针(相比红黑树的左右子节点指针,内存开销接近)。
- 红黑树:每个节点需存储颜色标志、左右子节点指针,实际内存占用与跳表差异不大。
6. 并发优化的潜力
- 跳表:可以通过细粒度的锁或无锁编程(如 CAS)优化并发修改。
- 红黑树:平衡操作涉及全局结构调整,并发优化难度大。
为什么不是所有场景都用跳表?
- 红黑树的优势:严格平衡,查询性能更稳定(跳表的层数依赖随机数)。
- 其他数据库的选择:如 MySQL 的索引使用 B+ 树(磁盘友好),而内存数据库(如 Redis)优先考虑内存操作效率。
总结
Redis 选择跳表而非红黑树,核心原因是:
- 插入/删除更高效:无需再平衡,适合高频写操作。
- 范围查询更优:直接遍历链表即可。
- 实现简单:降低代码维护成本。
- 契合场景:ZSet 的典型操作(如排行榜)更依赖顺序访问。
虽然红黑树的查询性能理论上更稳定,但跳表在综合性能、实现复杂度和功能需求上更胜一筹。
消息队列
mq了解过吗?解决哪些问题
消息队列(Message Queue, MQ)是分布式系统中广泛使用的中间件技术,主要用于解决系统间的异步通信、解耦、流量削峰等问题。以下是消息队列的核心作用、典型场景及主流产品对比:
一、消息队列解决的4大核心问题
1. 系统解耦
- 问题:服务间直接调用(如RPC)会导致强耦合,任一服务宕机或变更可能引发连锁故障。
- 解决方案:生产者将消息发送到MQ,消费者独立订阅并处理,双方无需感知彼此的存在。
- 场景:
- 电商订单系统:订单服务生成订单后,通过MQ通知库存服务扣减库存、支付服务处理支付,各服务独立演进。
- 用户注册:注册服务完成数据写入后,通过MQ触发发送欢迎邮件、初始化用户画像等操作。
2. 异步处理
- 问题:同步阻塞调用(如HTTP请求)导致响应延迟,资源利用率低。
- 解决方案:非关键流程异步化,生产者发送消息后立即返回,消费者异步处理。
- 场景:
- 用户下单后,前端立即返回“订单创建成功”,后台异步处理物流调度、短信通知等耗时操作。
- 视频上传:用户上传视频后,系统异步进行转码、审核、生成缩略图等操作。
3. 流量削峰
- 问题:突发流量(如秒杀活动)超过下游系统处理能力,导致服务崩溃。
- 解决方案:MQ作为缓冲区,平滑流量峰值,按下游处理能力消费消息。
- 场景:
- 秒杀系统:瞬间涌入的10万请求写入MQ,库存服务按每秒1000件的速率消费,避免数据库被击穿。
- 日志收集:业务高峰期的日志批量写入MQ,下游日志分析服务逐步消费。
4. 数据最终一致性
- 问题:分布式事务实现复杂,跨服务数据一致性难以保证。
- 解决方案:通过MQ的可靠投递和重试机制,结合本地事务表,实现最终一致性。
- 场景:
- 跨行转账:A银行扣款成功后,通过MQ通知B银行入账,若失败则重试直到成功。
- 订单状态同步:订单支付成功后,通过MQ同步状态至物流系统,确保双方数据最终一致。
二、消息队列的典型应用场景
| 场景 | 技术实现 | 代表MQ |
|---|---|---|
| 实时日志处理 | 日志采集 -> MQ -> 流式计算(Flink/Spark) | Kafka |
| 微服务异步通信 | 服务间通过MQ解耦,如订单通知库存 | RabbitMQ |
| 金融交易消息分发 | 高可靠事务消息、顺序消息 | RocketMQ |
| IoT设备数据采集 | 海量设备数据汇聚与分发 | EMQX(MQTT协议) |
三、主流消息队列对比
| 产品 | 吞吐量 | 延迟 | 可靠性 | 适用场景 | 核心特性 |
|---|---|---|---|---|---|
| Kafka | 超高 | 毫秒级 | 高(持久化) | 日志收集、大数据流处理 | 分区顺序性、持久化存储、高吞吐 |
| RabbitMQ | 中 | 微秒级 | 高 | 企业级异步通信、复杂路由 | 灵活的路由规则、ACK机制、死信队列 |
| RocketMQ | 高 | 毫秒级 | 极高 | 金融交易、订单处理 | 事务消息、顺序消息、消息回溯 |
| ActiveMQ | 低 | 毫秒级 | 中 | 小型系统、传统JMS应用 | 支持JMS协议、多语言客户端 |
| Pulsar | 高 | 毫秒级 | 高 | 多租户消息平台、云原生场景 | 分层存储、低延迟、多租户隔离 |
分布式
1. CAP为什么只能同时满足两个?
CAP定理指出,在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance) 三者无法同时满足,最多只能实现其中两个。其核心原因是 网络分区(Network Partition)是分布式系统的必然风险,而面对分区时,系统必须做出取舍。
通俗解释:
想象一个分布式系统有两个节点A和B,存储同一份数据。
- 场景1:网络正常
- A和B可以通信,系统可以同时保证一致性(数据相同)和可用性(都能响应请求)。
- 场景2:网络断开(分区)
- A和B无法通信,此时系统必须选择:
- 选择一致性(CP):如果用户写入A,但A无法同步到B,则系统会拒绝写入或阻塞,保证数据一致,但牺牲可用性(用户可能无法得到响应)。
- 选择可用性(AP):允许用户继续读写A和B,但可能导致数据不一致(A和B的数据不同)。
- A和B无法通信,此时系统必须选择:
技术本质:
- 分区是客观存在的:网络故障无法完全避免(如光纤被挖断、交换机故障)。
- 一致性与可用性矛盾:
- 要保证一致性,必须所有节点达成共识(需通信),但分区时无法通信,只能阻塞或拒绝请求(牺牲可用性)。
- 要保证可用性,必须允许节点独立响应,但可能返回旧数据(牺牲一致性)。
CAP的常见取舍:
| 选择 | 典型系统 | 场景 |
|---|---|---|
| CP | ZooKeeper、etcd | 金融交易、配置管理(强一致性) |
| AP | Cassandra、Redis | 社交网络、实时统计(高可用) |
| CA | 单机数据库(如MySQL) | 无分区的单点系统(非分布式) |
设计模式
单例模式
在Java中,单例模式确保一个类只有一个实例,并提供一个全局访问点。以下是几种常见的单例模式实现方式及其适用场景:
1. 饿汉式(线程安全)
特点:类加载时立即初始化实例,简单但可能浪费资源。
|
|
2. 懒汉式(线程不安全 → 需加锁)
特点:延迟初始化,需解决多线程安全问题。
|
|
3. 双重检查锁定(DCL,线程安全)
特点:减少同步开销,需用 volatile 防止指令重排序。
|
|
关键点:
volatile防止new Singleton()的指令重排序。- 双重检查减少同步块执行次数。
单例模式使用场景有哪些呢?举个例子
AI Infra
训练
大模型算法和训推框架基础:B站视频@ZOMI酱和@五道口纳什
推理
vLLM
大模型推理框架
一篇入门好文,来自百度内网:从PagedAttention到调度器:vLLM高效推理全链路揭秘
LLM
Transformer
讲讲Transformer模型
注意力计算可表示为:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$What the Single-Head Attention really is?
Transformer的第一步是将输入的每一个token通过 embedding 转换成一个高维空间中的嵌入向量 $\overrightarrow {E_i}$。Transformer的目标是将逐步调整 $\overrightarrow {E_i}$ 使得它们不单单编码单个token,还能融入更丰富的上下文含义。就比如一个名词会问前面的词中有没有形容词啊,这样的提问就被编码成了所谓的查询向量 $\overrightarrow {Q_i}$。而前面的词想要回答后面的哪些查询提问,则被编码成了所谓的键向量 $\overrightarrow {K_i}$。所以这个 $\overrightarrow {Q_i}$ 和 $\overrightarrow {K_i}$ 的点积和的大小,就是衡量每个键和每个查询的匹配程度。而前面的一个比如形容词,需要把后面的名词调整到什么程度,就被编码成了所谓的值向量 $\overrightarrow {V_i}$。所以将上面计算出来的每一个查询的匹配程度,通过softmax函数转换成一个概率分布向量,作为权值再乘以值向量 $\overrightarrow {V_i}$,将上面的这个结果进行求和,得到的就是嵌入向量的调整值 $\Delta\overrightarrow { E_i}$,再将调整值加到原始嵌入向量上,便得到一个编码了更丰富的上下文信息的向量 $\overrightarrow {E_i} + \Delta\overrightarrow { E_i}=\overrightarrow {E_i^{\prime}}$。
-
$\overrightarrow {E_i}$:嵌入向量。初始嵌入向量只编码了该token的含义以及该词的位置信息,和上下文没有关联。(在GPT3中是 $12288$ 维)
-
$Q$:由查询向量 $\overrightarrow {Q_i}$ 组成的查询矩阵。通过使用一个查询投影矩阵 $W_Q$ 乘以嵌入向量 $\overrightarrow {E_i}$ 得到查询向量 $\overrightarrow {Q_i}$。(注意:$\overrightarrow {Q_i}$ 的维度要比 $\overrightarrow {E_i}$ 小的多,例如只有 $128$ 维,所以它会将嵌入向量映射到低维度空间)
-
$K$:由键向量 $\overrightarrow {K_i}$ 组成的键矩阵。通过使用一个键投影矩阵 $W_K$ 乘以嵌入向量 $\overrightarrow {E_i}$ 得到键向量 $\overrightarrow {K_i}$。
-
$d_k$:查询向量 $\overrightarrow {Q_i}$ 和键向量 $\overrightarrow {K_i}$ 的维度。
-
$\text{softmax}()$:将数值向量归一化为一个概率分布向量。
-
$V$:由值向量 $\overrightarrow {V_i}$ 组成的值矩阵。通过使用一个值投影矩阵 $W_V$ 乘以嵌入向量 $\overrightarrow {E_i}$ 得到值向量 $\overrightarrow {V_i}$。
通过下一个词如果输出了
大模型返回结果不要用JSON,而是使用XML,返回结果出错概率更低。
知识星球:大模型面试宝典(作为学习指南,而不是像小林coding那种八股)
agent开发方向项目:
- 智能客服
- 复现一下openmanus的本地部分
Transformer时间复杂度是多少呢
Transformer模型的时间复杂度主要由其核心组件自注意力机制和**前馈网络(FFN)**决定。以下是详细分析:
1. 自注意力机制的时间复杂度
自注意力机制的核心是计算查询(Q)、键(K)、值(V)矩阵的交互:
- 输入:序列长度 nn,每个 token 的维度 dd。
- 计算步骤:
- QKᵀ 矩阵乘法:计算 Q⋅KTQ⋅K**T,时间复杂度为 O(n2d)O(n2d)。
- Softmax 和缩放:时间复杂度 O(n2)O(n2),可忽略。
- 与 V 矩阵乘法:将注意力权重与 VV 相乘,时间复杂度 O(n2d)O(n2d)。
- 总时间复杂度:O(n2d)O(n2d)。
多头注意力(Multi-Head Attention)通过将 dd 拆分为 hh 个头(每个头维度 d/hd/h),但总时间复杂度仍保持 O(n2d)O(n2d),因为每个头的计算量总和与原单头一致。
2. 前馈网络(FFN)的时间复杂度
- 输入:序列长度 nn,维度 dd。
- 结构:两个线性层(通常从 dd 扩展到 4d4d 再压缩回 dd)。
- 时间复杂度:O(nd2)O(n**d2)(每个 token 独立计算)。
3. 整个 Transformer 层的复杂度
每个 Transformer 层包含 1 个自注意力 + 1 个 FFN:
- 单层时间复杂度:O(n2d+nd2)O(n2d+n**d2)。
- L 层模型总复杂度:O(Ln2d+Lnd2)O(L**n2d+Lnd2)。
4. 主导项分析
- 当 n≫d*n*≫*d*(长文本场景):主导项为 O(Ln2d)O(L**n2d)。
- 当 d≫n*d*≫*n*(高维特征场景):主导项为 O(Lnd2)O(Lnd2)。
5. 与其他模型的对比
| 模型 | 时间复杂度 | 并行性 |
|---|---|---|
| Transformer | O(n2d)O(n2d) | 完全并行 |
| RNN | O(nd2)O(n**d2) | 无法并行 |
| CNN | O(knd2)O(kn**d2) | 局部并行 |
- Transformer 的劣势:序列长度 nn 的平方增长导致长文本计算代价高。
- 改进方案:稀疏注意力(如 Longformer)、分块计算(如 Reformer)等优化方法可降低复杂度至 O(nlogn)O(nlogn) 或线性 O(n)O(n)。
总结
Transformer 的时间复杂度为:
O(Ln2d+Lnd2)O(L**n2d+Lnd2)
实际应用中,长序列(nn 大)时 O(n2d)O(n2d) 是主要瓶颈,而通过模型优化(如稀疏化)可缓解这一问题。
Transformer的BERT有了解过吗
是的,我对BERT(Bidirectional Encoder Representations from Transformers)非常熟悉。它是基于Transformer架构的预训练模型,由Google在2018年提出,彻底改变了自然语言处理(NLP)领域的多项任务。以下是针对面试可能涉及的BERT核心知识点整理:
1. BERT的核心思想
- 双向上下文建模: 与传统语言模型(如GPT)不同,BERT通过Masked Language Model (MLM) 同时利用左右两侧的上下文信息,从而捕捉更丰富的语义。
- Transformer Encoder: 仅使用Transformer的Encoder堆叠(无Decoder),每一层包含自注意力机制和前馈网络。
2. 关键技术与训练任务
(1) Masked Language Model (MLM)
- 随机遮盖输入词的15%,模型预测被遮盖的词(如:“I [MASK] a student” → “am”)。
- 改进:10%替换为随机词,10%保留原词,缓解预训练-微调不一致性。
(2) Next Sentence Prediction (NSP)
- 二分类任务:判断两个句子是否连续(如:"[CLS] Sentence A [SEP] Sentence B [SEP]" → IsNext/NotNext)。
- 用途:提升模型理解句子间关系的能力(后续研究如RoBERTa发现NSP可能非必要)。
3. 模型结构细节
- 输入表示:
[CLS]:分类任务的特殊标记(其输出用作聚合表示)。[SEP]:分隔句子对。- Token Embedding + Segment Embedding + Position Embedding(三嵌入求和)。
- 层数与参数量:
- BERT-base:12层Transformer,隐藏层维度768,12个头,参数量约110M。
- BERT-large:24层,隐藏层1024,16个头,参数量约340M。
4. 微调(Fine-tuning)应用
- 任务适配:通过添加任务特定输出层,BERT可应用于多种下游任务:
- 文本分类(如情感分析):使用
[CLS]输出。 - 序列标注(如NER):对每个token的输出分类。
- 问答任务(如SQuAD):预测答案段的起止位置。
- 句子对任务(如语义相似度):联合处理两个句子。
- 文本分类(如情感分析):使用
5. BERT的优缺点
优点:
- 强大的泛化能力:预训练捕捉深层语言特征,微调所需数据少。
- 多任务统一架构:同一模型可处理分类、标注、生成等任务(需调整输出层)。
缺点:
- 计算资源消耗大:预训练需要大规模GPU/TPU集群。
- 长文本处理受限:因自注意力的O(n2)O(n2)复杂度,序列长度通常限制为512。
- 生成能力弱:无Decoder,不擅长文本生成(需结合GPT或Seq2Seq结构)。
6. 常见面试问题与回答思路
Q1: BERT为什么比GPT效果好?
- 关键点:GPT是单向(从左到右)的生成模型,而BERT通过双向上下文捕捉更全面的语义信息。
- 举例:在预测"bank"时,BERT能同时利用"river"和"money"的上下文,而GPT仅能看到左侧信息。
Q2: BERT的参数量如何估算?
- 公式:参数量 ≈ L×(12d2+13d)L×(12d2+13d)(L为层数,d为隐藏层维度)。
- BERT-base示例:12层 × (12×768² + 13×768) ≈ 110M。
Q3: 如何优化BERT的长文本处理?
- 回答方向:
- 稀疏注意力(如Longformer的滑动窗口注意力)。
- 分块+池化(如将文本分段后聚合表示)。
- 层次化建模(如先处理句子再处理文档)。
7. 扩展:BERT的变体模型
- RoBERTa:移除NSP,更大批次/更多数据训练。
- ALBERT:参数共享与嵌入分解,降低内存占用。
- DistilBERT:知识蒸馏压缩模型。
- ELECTRA:用生成器-判别器架构替代MLM,提升训练效率。
BERT与GPT核心区别总结
一、架构设计
- BERT
- 基于Transformer的Encoder-only架构,强调双向上下文理解35
- 输入支持句子对(如问答对),通过双向注意力机制捕捉全局语义18
- GPT
- 基于Transformer的Decoder-only架构,采用单向自回归生成模式34
- 仅依赖已生成的上文预测下一个词,无法获取未来词的上下文信息58
二、训练机制
| 模型 | 预训练任务 | 训练目标 | 特点 |
|---|---|---|---|
| BERT | 掩码语言模型(MLM)+ 下一句预测(NSP)37 | 预测被遮蔽词及判断句子间连续性68 | 通过双向训练全面学习语义关系56 |
| GPT | 自回归语言模型 | 最大化下一个词的概率36 | 单向生成导致上下文理解受限48 |
三、应用场景
- BERT适用领域
- 文本理解类任务:情感分析、命名实体识别、语义匹配15
- 需捕捉双向上下文语义的场景(如问答系统)67
- GPT适用领域
- 文本生成类任务:对话系统、文本补全、机器翻译56
- 强调生成连贯性而非深度理解的场景(如故事创作)18
四、上下文处理能力
- BERT:双向建模使其能同时分析前后文关联,对复杂语义关系(如反讽、指代)捕捉更强37
- GPT:单向生成模式限制了上下文理解,但生成连贯性优于双向模型56
五、模型输出
- BERT:输出上下文相关的词向量,需微调适配下游任务16
- GPT:直接输出生成文本序列,适用于端到端的生成式应用38
典型应用对比示例
| 任务类型 | BERT优势场景 | GPT优势场景 |
|---|---|---|
| 文本分类 | ✔️(情感极性分析)5 | - |
| 文本生成 | - | ✔️(自动摘要生成)6 |
| 问答系统 | ✔️(答案抽取型任务)7 | ✔️(开放域对话型任务)8 |
核心结论
- BERT更适合需要深度语义理解的任务,通过双向编码获取全局信息78
- GPT更擅长生成连贯文本,但需权衡其上下文理解局限性56
- 实际应用中,两者常结合使用(如BERT生成特征输入GPT)以平衡理解与生成能力
RAG
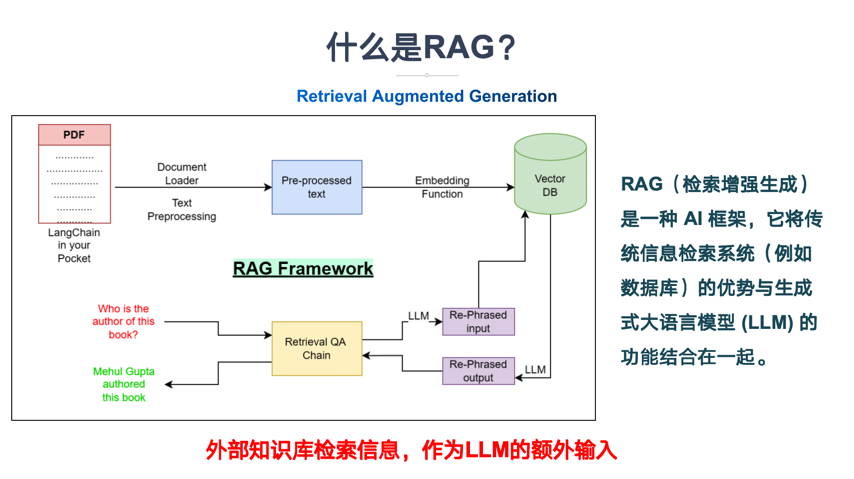
思维题
赛马题
面试反问
前述
针对自己在秋招的面试中,根据自己面试情况中,在后面的面试复盘中,针对于面试官要求最后的反问环节的一些注意细节,从反问的角度对于下面问题:
- 我们应该如何进行提问?
- 应该分别针对不同阶段的面试提问哪些内容?
- 提问上应该抱有那些心态?
- ……
自己从每次面试,这里做一次简单的总结分享一下,希望能帮助到各位同学。
一面:纯技术面
目的
对于技术面来说,一面主要是进行基础的技术面,涉及到你对该方向的基础知识的掌握程度。比如软开:会涉及到对于
- 计算机的基础知识的掌握情况:让你说说操作系统,网络方面的知识等;
- 编程能力的熟悉程度:相应手撕几道编程题目;
- 编程语言的理解程度:比如对于你所熟悉的编程语言,如
CPP或者jave会让你说一些这些语言底层的机制是如何如何等等问题。
反问
技术层面上反问:
- 比如刚刚面试中有遇到自己不太清楚的问题,或者答的不太好的问题点,自己可以问下:您刚才问的xxx问题,我想问下您的思路?
- 比如自己和面试的部门的匹配程度:部门的主营业务和使用的技术栈都是哪些(组里面进去的新人一般做哪些任务)?岗位主要负责的业务?
- 当前部门的一个大概分工方向?部门主要的架构?
能力层面上的反问:
- 就我的这次面试,您觉得我的能力有哪些地方(比如技术上或者语言表达能力上)需要提升?
- 面试一般多久会通知结果?
二面:技术综合面/主管面
目的
二面一般是一个部门的小领导或者一个主管来进行面试的(大部分情况是这样的),等顺利进入改公司的时候,也大概率是你的领导或者小组长之类的。二面的出发点,表明你的一面技术基础面是OK的,至少对于该公司来说是基本够用。
二面综合面,会相应对的技术综合实力来进行考量的,
- 一搬会根据你的项目经历,结合你的技术来深入项目细节展开交流,所以你一定得对的项目所涉及的知识网非常熟悉方可。
- 同时,会结合你的项目,穿插一些情景类的技术问题,让你说一下自己的解决思路和想法。我认为这也是一个和面试官进行交互想法的过程,不懂的也可以问,互相讨论感觉效果更好(不乏有的面试官总向咄咄逼人😅)
反问
从综合层面上的反问:
- 面试的候选人,特别是对于我们这样的校招生,企业一般最看重什么?
- 您对进入您团队的成员的要求是什么?或者说,我们需要具备哪些能力才能胜任这个岗位?
- 团队工作氛围?
三面:HR面
目的
如果能顺利进入HR面,也意味着你是较大可能的能顺利拿到该家公司的offer了👏。
HR也仅仅是考一下的个人软能力方面的问题。
反问
- 公司对新人的培养模式是什么样的?
- 公司氛围?
- 一般情况大概多久可以出结果?(这时候,应该去想
HR确认最终什么时候出结果,后续的还有那些流程等)
面试历程时间表
| 1面 | 2面 | 3面 | hr面 | 评价 | ||
|---|---|---|---|---|---|---|
| 日常实习 | wxg-微信支付-后台开发 | 2025.4.7 一面秒挂 | 处子面,hot100没做出来 | |||
| IEG-游戏安全-后台开发 | 2025.4.15 | 2025.4.17 | 2025.4.18 技术三面挂(周一挂) | |||
| 百度-医疗健康业务部-算法 | 2025.4.30一面秒挂 | |||||
| IEG-游戏营销技术服务-运营开发 | 想蹲一个后台开发,拒面了 | |||||
| 美团-大模型数据开发实习生 | 2025.4.29 | 2025.5.6 (一周后挂) | (感觉做爬虫没意思+北京租房无补贴)和面试官表示不想来 | |||
| 字节-今日头条-用户增长业务-后端 | 2025.5.9(一周挂) | |||||
| wxg-技术架构-后台开发 | 2025.5.28 | 2025.6.5 (面完秒挂) | 流程奇慢无比,每次面试四道算法题90min+… | |||
| 美团-大模型应用系统开发实习生(智能分析方向) | 2025.5.29 | 2025.5.30(默挂) | ||||
| 快手-直播-Java开发 | 2025.6.6 | 2025.6.10(默挂) | ||||
| 淘天-客户端开发-ai agent方向 | 2025.6.20电话面(默挂) | |||||
| 美团-大模应用平台研发项目实习生 | 2025.6.30(一周挂) | |||||
| 百度-搜索架构-基础召回 | 2025.7.8 | 2025.7.9 | 2025.7.10晚hr电话 | 接offer了,也算转c++了 | ||
| 高德-大模型应用开发实习生(工程效率方向) | 2025.7.8(默挂) | |||||
| 美团-软件开发实习生 | 2025.7.8(一周挂) | |||||
| 苏州微软-Bing-intern developer | 2025.7.10 | 2025.7.11(默挂) | 第一次遇到早上九点和十点面试的… | |||
| IEG-游戏营销技术服务-运营开发 | 2025.7.10(一周挂) | |||||
| 米哈游-研发效能-后端 | 2025.7.17 | 已拿到百度offer已拒面 | ||||
| 暑期实习 | wxg-基础微信团队 | 2026.1.16(当晚挂) | 做agent的,用的c++,好奇怪的组合,不感兴趣 | |||
| 小红书-引擎架构部-大模型架构基础训练 | 2026.1.26(当晚挂) | 想试试ai infra,但是这个真的是我面试以来问的最难的了,好崩溃基本上一题都没答出来 | ||||
| 美团-MLP-推理 | 2026.2.2(面试一小时后约二面) | 2026.2.3 | 2026.2.3加微信沟通 | |||
| 快手-AI Infra | 2026.2.5 | 自我介绍完发现被hr推错了团队,推到了agent团队了,面试官说我适合训推,直接5min结束等待hr下面约面 | ||||
| 字节-AML-训练 | 2026.2.9 | 由于美团在2.9上午发了offer,所以为了不影响面评,直接和hr取消了面试,等待秋招有缘再面 | ||||